swig(pyrfr)
1
apt-get install swig --fix-missing
若提示
1
2
3
4Reading package lists... Done
Building dependency tree
Reading state information... Done
E: Unable to locate package swig先更新源:
1
apt-get update
再安装swig。
lazy_import-0.2.2(auto-sklearn)
vim setup.py
1
with open('README.rst') as infile:
改为:
1
with open('README.rst', encoding='utf-8') as infile:
python setup.py install
升级cmake(xgboost)
下载源码https://github.com/Kitware/CMake/releases/download/v3.20.4/cmake-3.20.4.tar.gz
编译安装
1
2
3./boostrap
make
make install添加软连接
1
ln -s /usr/local/bin/cmake /usr/bin/cmake
查看
1
cmake --version
1
2
3
4root@3790ed27be82:~/cmake-3.20.4# cmake --version
cmake version 3.20.4
CMake suite maintained and supported by Kitware (kitware.com/cmake)
numpy==1.19.4
1.19.5暂时会有bug。报错
1
2>>> import numpy as np
Illegal instruction (core dumped)
Orientdb 基本操作
1. 连接数据库
2
3
config = Config.from_url(server, user, pwd)
g = Graph(config)
2. 构造schema类
2
3
4
5
6
7
8
9
10
11
Relationship = declarative_relationship()
# 定义节点类,继承Node;定义关系时,继承Relationship
class OrientdbFile(Node):
element_type = 'file' # 表名
element_plural = 'files' #
file_id = Integer(nullable=False, unique=True)
emp_no = Integer(nullable=True, unique=False)
file_type = String(nullable=True, unique=False)
初始化schema
1
2g.create_all(Node.registry) # 创建节点
g.create_all(Relationship.registry) # 创建边绑定schema
若orientdb中已存在表,则只需要绑定相应的表即可。
from class
1
2g.include(Node.registry) # 绑定节点
g.include(Relationship.registry) # 绑定边from schema
1
2
3
4
5
6
7classes_from_schema = graph.build_mapping(
Node,
Relationship,
auto_plural = True)
# Initialize Schema in PyOrient
graph.include(classes_from_schema)
3. 插入数据
orientdb里,一条记录可以认为是表对象的一个实例。插入记录即新建一个对象实例。有两种方式实现。
使用broker
1
g.persons.create(id="1", name="张三")
1
2p = {"id": "2", "name": "李四"}
Person.objects.create(**p)原生方式
1
2p = {"id": "3", "name": "王五"}
g.create_vertex(Person, **p)
4. 查询数据
方式一
1
2
3result = g.persons.query().all()
for p in result:
print(p.id, p.name)1
2
31 张三
2 李四
3 王五方式二
1
2
3result = g.query(Person).all()
for p in result:
print(p.id, p.name)1
2
31 张三
2 李四
3 王五filter
1
result = g.persons.query(name='张三').all()
1
result = g.query(Person).filter(Person.name == "'张三'").all() # 备注:张三内层同样需要用引号包裹起来,源代码的问题,所以建议使用上面方式。
5. 修改数据
pyorient的ogm本身并没有实现update功能,可以简单通过删除后插入实现修改功能。
1 | ps = g.persons.query(name='张三').all() |
1 | 2 李四 |
6. 删除数据
1 | p_dict = {"name": "张三"} |
7. batch
批量操作
1 | batch = g.batch() |
1 | 李四 2 |
备注:
batch的key不能为纯数字,例如batch[‘12’],当然,batch[12]更不行。报错timeout,不解释。
batch的key必需明确,否则会不提交到库。
1
2
3
4
5
6
7
8batch = g.batch()
for i in range(10, 11):
batch.persons.create(name='name' + str(1), id=i)
batch.commit()
result = g.persons.query(id=10).all()
for r in result:
print(r.name, r.id)并没有任何输出,表明,记录并没有正确提交。
pycharm+Ubuntu20.04
ubuntu20.04 安装pycharm遇到的问题
pycharm2019.3不能输入中文
无解,网上试过各种办法均不能解决。升级至pycharm2021专业版解决问题,可以输入中文,但是中文提示光标不跟随,一直龟缩在左下角,严重影响体验。
pycharm2021 中文光标不跟随问题
下载工具:链接: https://pan.baidu.com/s/1WLYPbtMfqpaJxcb8YbT1sw 密码: ddaf
解压
在pycharm的安装目录的pycharm.sh加入已下内容

pycharm2021专业版激活
下载插件:链接: https://pan.baidu.com/s/1scwJQySV333_g086NQodVw 密码: pth0
从本地安装插件,不解压,直接选择压缩包
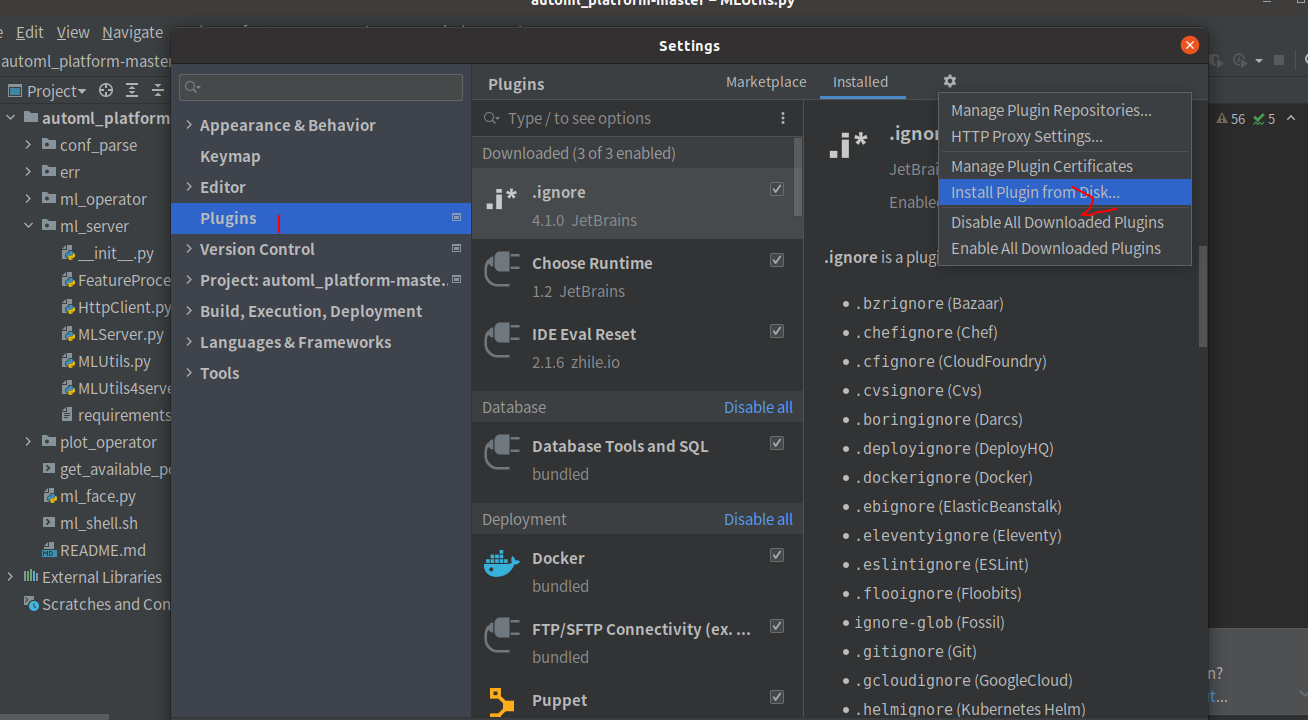
help->Eval Reset
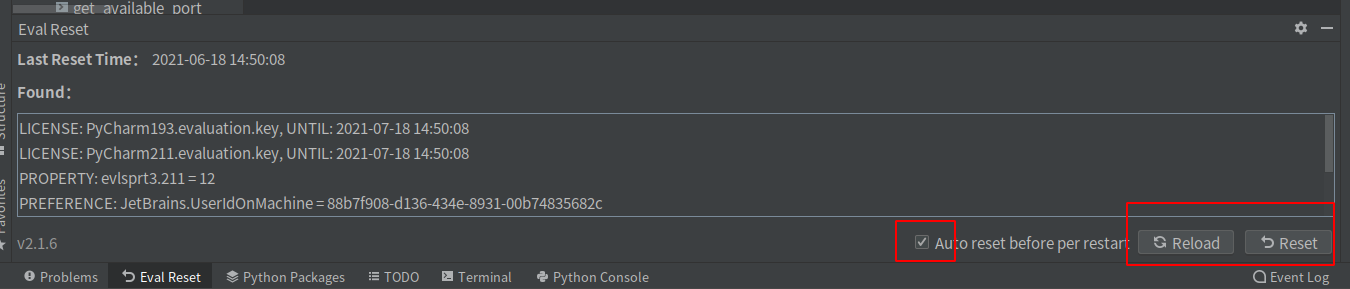
每次启动ide,会自动重置试用时间。达到无限激活的功能。
rasa总结文档
1. 基本命令
1.1 训练模型
无论是单独训练,还是2个模型一起训练,均可以使用rasa train命令实现(rasa nlu和rasa core合并为RASA),不同之处在于,提供的训练数据,若同时提供两份数据,则会同时训练nlu和core。
训练nlu模型
1
python -m rasa train --config configs/zh_jieba_supervised_embeddings_config.yml --domain configs/domain.yml --data data/nlu/number_nlu.md data/stories/number_story.md
训练core模型
1
python -m rasa train --config configs/zh_jieba_supervised_embeddings_config.yml --domain configs/domain.yml --data data/stories/number_story.md
一起训练两个模型
1
python -m rasa train --config configs/zh_jieba_supervised_embeddings_config.yml --domain configs/domain.yml --data data/nlu/number_nlu.md data/stories/number_story.md
1.2 启动rasa
不额外独立nlu服务
1
python -m rasa run --port 5005 --endpoints configs/endpoints.yml --credentials configs/credentials.yml
启动额外nlu服务
1
python -m rasa run --port 5005 --endpoints configs/endpoints.yml --credentials configs/credentials.yml --enable-api -m models/nlu-20190515-144445.tar.gz
单独启动nlu服务
1
rasa run --enable-api -m models/nlu-20190515-144445.tar.gz
调用第三方模型服务
1
rasa run --enable-api --log-file out.log --endpoints my_endpoints.yml
在my_endpoints.yml中配置rasa模型的url
1
2
3models:
url: http://my-server.com/models/2019-1222.tar.gz
wait_time_between_pulls: 10 # [optional](default: 100)rasa模型还可以存放在S3 , GCS and Azure Storage 云盘中,同样远程调用,这里不多赘述。
nlu服务开启后,post方式调用
post http://localhost:5005/model/parse
1 | input: |
1.3 启动action
2. NLU
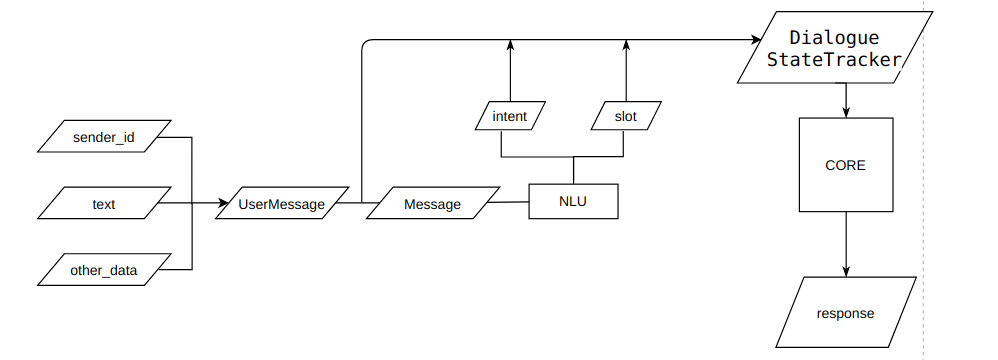
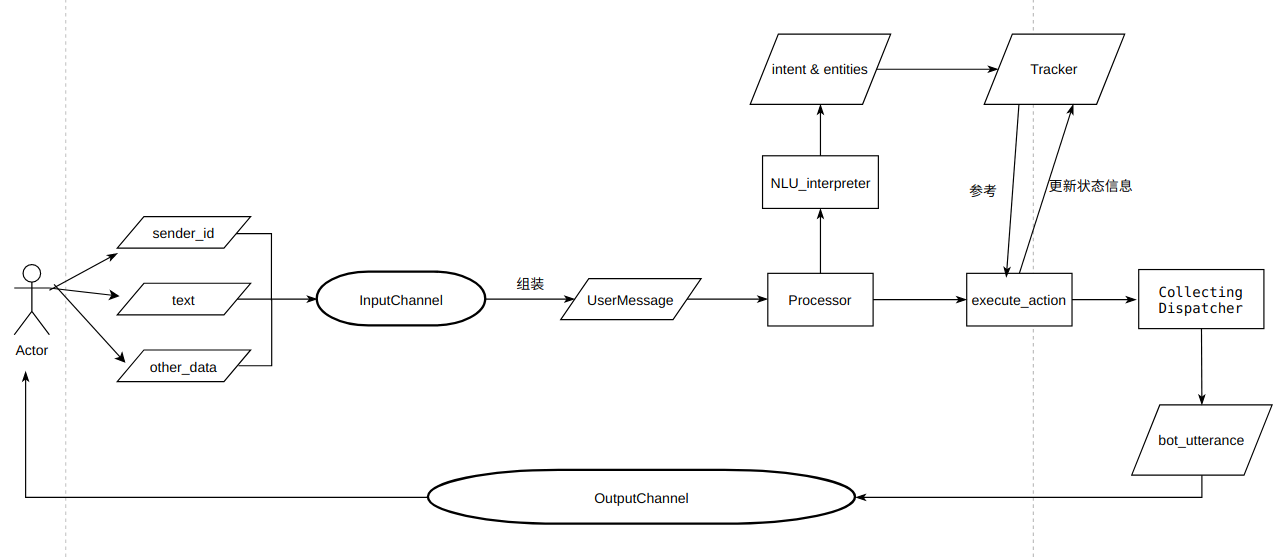
2.1 数据格式
rasa支持markdown和json两种数据格式,同时提供了相互转化的命令。
nlu训练数据包含四个部分:
Common Example
唯一必须提供数据。由三部分组成:intent、text、entities。
## intent: 你的意图名称
- text
text中可以不包括实体,如果有实体使用
[entityText](entityName)来标记。synonyms
Regular Expression Features
lookup tables
2.2 数据转化
rasa提供了json和markdown格式的转化命令
1 | usage: rasa data convert nlu [-h] [-v] [-vv] [--quiet] --data DATA --out OUT |
example:
3. core
备注1: core模型是一个分类分为,类别数为domain中定义的action数。action主要分为以下4类:
custom action
utterance:response、template
default actions
[‘action_listen’, ‘action_restart’, ‘action_session_start’, ‘action_default_fallback’, ‘action_deactivate_form’, ‘action_revert_fallback_events’, ‘action_default_ask_affirmation’, ‘action_default_ask_rephrase’, ‘action_back’]
forms(表单)
action类别为各类action取交集后的结果。
备注2:用户可以直接像core发送请求,不经过nlu模块。参数格式:/intent{“entityName”: “entityValue”, …}
2
3
4
"sender": "kkkkkkk",
"message": "/search_treat{\"disease\":\"丛集性头痛\", \"sure\":\"丛集性头痛\"}"
}
2
3
4
5
6
7
8
9
10
{
"recipient_id": "kkkkkkk",
"text": "丛集性头痛的简介:从集性头痛(clusterheadaches)亦称偏头痛性神经痛、组胺性头痛、岩神经痛、蝶腭神经痛、Horton头痛等,.病员在某个时期内突然出现一系列的剧烈头痛。一般无前兆,疼痛多见于一侧眼眶或(及)额颞部,可伴同侧眼结膜充血、流泪、眼睑水肿或鼻塞、流涕,有时出现瞳孔缩小、垂睑、脸红、颊肿等症状。头痛多为非搏动性剧痛。病人坐立不安或前俯后仰地摇动,部分病员用拳击头部以缓解疼痛。"
},
{
"recipient_id": "kkkkkkk",
"text": "丛集性头痛的治疗方式有:药物治疗、支持性治疗"
}
]
vim常用命令总结
vim常用命令
- 行内移动
- w: 向前移动(单词)
- b:向后移动(单词)
- $: 移动到行末
- ^ :移动到行首
- 跨行移动
- ↑,↓
- 数字+方向键:5↓代表向下移动5行
- ctrl+f:向前翻页
- ctrl+b:向后翻页
- G(shift+g):移动到文件末尾
- gg:移动到文件开头
- N+%:移动到文件的N%处,50+%表示移动到文件的中间位置
- N+g:移动到文件的N行处,10+g表示移动到第10行。
- 定向移动(查找)
- /text:查找text,使用n/N 向下/向上跳转。vim查找支持正则,如:/^$查找空白行。
- 文件格式与编码
- :set list :显示制表符和行尾, :set nolist:取消显示
- :set nu(number) :显示行号,:set nonumber 取消显示
- :set fileencoding:查看当前文件编码,当vim无法识别编码的时候,默认实用latin-1读取。:e ++enc=gb18030 强制使用gb18030编码重新打开。
- 分屏
- vim -o file1 file2: 打开两个文件(默认水平分屏)
- 已经打开vim的情况下,:vs file2: 打开file2,vs指vertical split。
- ctrl + w + ←(h)/↑(j)/↓(k)/→(l):控制调整的方向。
- ctrl + w+ w:跳转下一个窗口
- ctrl + w +c 关闭窗口
中文文本纠错调研
1. 常见的中文错误类型
发音错误, 特点:音近,发音不标准, 原因:地方发音,语言转化。 - 灰机
拼写错误:特点: 正确词语错误使用, 原因: 输入法导致-拼音、五笔、手写 - 眼睛蛇
语法,知识错误: 特点:逻辑错误,多字、少字,乱序 - 女性患病前列腺炎
2. 研究现状
2.1 通用纠错项目
错误检测
- 常用字典匹配: 切词后不再常用字典中认为有错
- 统计语言模型:某个字的似然概率低于句子的平均值
- 混淆字典匹配:example - 国藉 -> 国籍
候选召回
- 近音字替换(拼音): 藉\ji -> 籍, 集, 寄。。。
- 近形字替换(五笔): 藉 -> 籍,藕,箱
候选排序
语言模型计算句子概率,取概率超过原句子切最大的
P(患者1天前体检发现脾动脉瘤)
P(患者1天前体检发现皮动脉瘤)
P(患者1天前体检发现劈动脉瘤)
2.2 学术界进展
基于序列标注的纠错
《 Alibaba at IJCNLP-2017 Task 1: Embedding Grammatical Features
into LSTMs for Chinese Grammatical Error Diagnosis Task 》利用序列标注模型 + 人工提取特征进行错误位置的标注
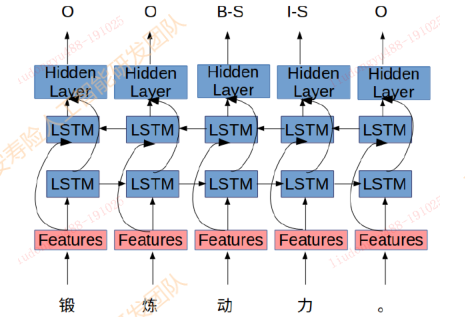
2017年IJCNLP举办的CGED比赛中阿里团队提出的Top1方案成绩: P:0.36, R: 0.21, F1:0.27
基于NMT的纠错
《 Youdao’s Winning Solution to the NLPCC-2018 Task 2 Challenge: A Neural
Machine Translation Approach to Chinese Grammatical Error Correction 》利用模型将错误语句翻译成正确语句,利用transformer模型完成端到端的纠错过程
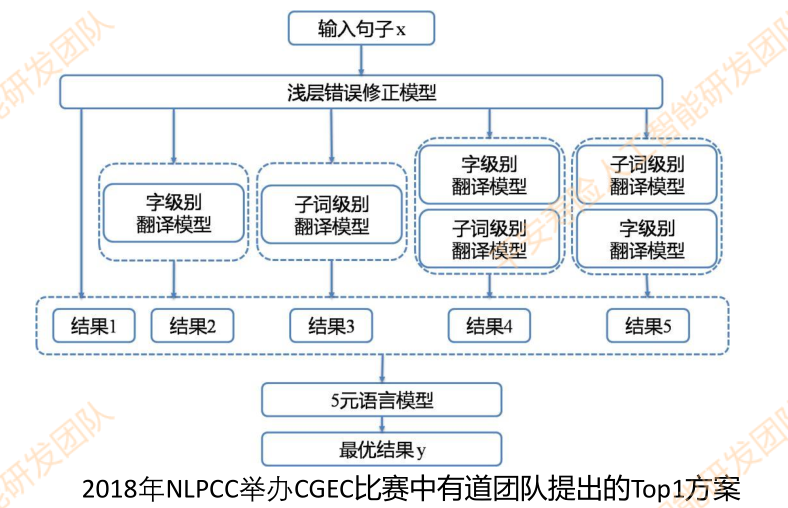
成绩: P: 0.34, R:0.18, F0.5: 0.29
2.3 评价指标
过纠率 / 误报率
$FAR = \frac{正确句子被纠错的个数}{正确句子的个数}$
召回率
$$R = \frac{错误句子被改正的句子数}{错误的句子总数}$$
纠错目标
被改正的句子数 >> 被改错的句子数
$$K * R >> (1 - K) * FAR$$
目标在于尽可能的提高召回率R。
2.4 存在的问题
公司目前纠错现状,还存在一下问题。
- 缺乏标注语料,难以展开基于深度学习的监督学习
- 纠错强调实时性,对内存和实效性要求很高,线上纠错不得超过10ms/句,导致大规模字典和复杂模型无法线上使用
- 纠错要求高准确性,宁愿牺牲召回也必须保证高准确度,防止过纠(把正确的词改错),过纠率不得高于0.2%
- 结合电子病历,绝大部分错误都是替换错误,同音字,同行字等。
3. 平安文本纠错方案
平安人寿问答纠错模块结构如下图所示。其基本流程包括错误检测、候选召回、候选排序、候选筛选。

3.1 错误检测
基于规则的错误检测
拼音匹配: 适合实体错误检测,比如疾病,药品等实体,需要维护拼音-实体隐射字典
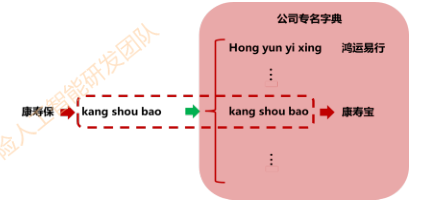
拼音编辑距离:1. 检测所有编辑距离小于阈值的路径 2. 最优路径选取(最小拼音编辑距离, 最长字符匹配)3. 语言模型 + 规则联合筛选
单双向2gram检测
当前词与上下文组成的2gram词频很低,认为有错
基于假设: 正确表述发生的频次要远远大于错误表述发生的次数
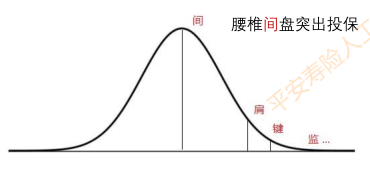
基于神经网络语言模型的错误检测
核心思想:
- 通过完形填空的方式预测候选字的概率分布
- 如果原字的概率不在topK或者top1比值操作阈值则认为有错
改进措施:
传统的语言模型从左到右,单向,只利用上文,改为双向模型,利用上下文信息。
传统的语言模型把预测字MASK,没有预测字的信息,可以改为引入当前字的混淆字信息(如:相似的字音和字形字)。
传统语言模型会直接预测字表,比如字表大小是3800,预测结果会直接得到3800个字的概率分布,其中大多是无用信息,且容易引发维度灾问题。可以通过将预测字约束在近音、近形和混淆字表里,提高效率和正确字与错误中字的区分度。

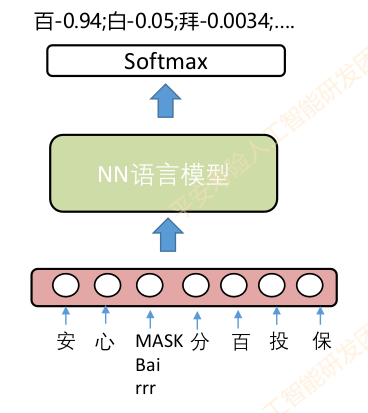
基于word2vec-cbow改造的音字混合受限字表示语言模型检测算法
基于CSLM的中文拼写检测:《Chinese Spelling Errors Detection Based on CSLM,2015》
主要特征:
- 带入预测字及上下文拼音、五笔特征
- 去掉前后鼻音和翘舌音,并利用混淆音集映射的方式来提高模型对谐音错误的识别性能。
- 预测字表受限于近音字、近形字和混淆字表中。

3.2 候选召回
近音字候选召回
选择近音字作为候选字,构造一个近音字字典。大规模的基础字典,使得在存储和读取速度方面收到了极大的调整。
字典存储构架如下:
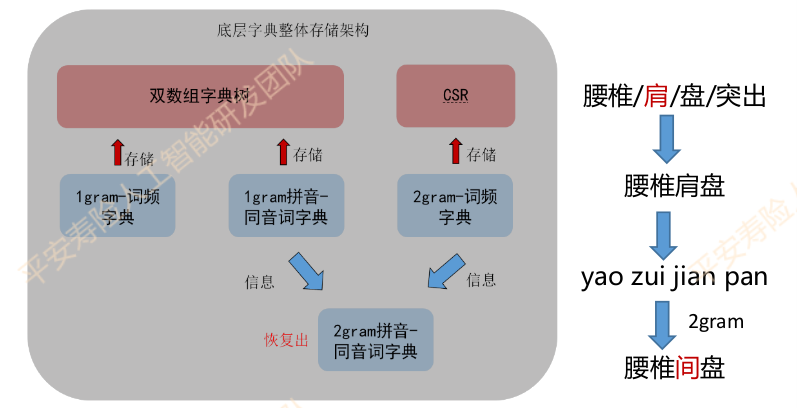
关键技术:
- 减低存储空间:
- 利用Trie树降低信息冗余
- 利用经典结合CSR压缩稀疏矩阵
- 使用词典间的关联信息回复2gram同音字典
- 提高读取速度:Trie树、CSR技术的高效索引。
- 减低存储空间:
字、音编辑距离召回
使用编辑距离作为是否召回的依据。
混淆词集
疾病口语词
3.3 候选排序
针对候选词的排序主要由二级排序来实现。
一级排序
模型:逻辑回归LR
作用:二级排序比较耗时,通过一级排序初筛出TopK进入下一级
要求:正类召回率高,运行速度快
特征:
- 频次比值:候选频次越高分数越高
- 编辑距离:编辑距离越小分数越高
- 拼音jaccard距离:拼音相近分数越高
- 4gram-LM概率差值:候选替换后橘子越通顺分数越高
一级排序大致流程如下:

例如:甲状腺==姐姐==该怎么治疗? ->==结节 0.99==
- 频次: 55 -> 94
- 编辑距离:2
- 拼音jaccard距离:0
- 语言模型概率:-21.9 -> -8.6
二级排序
模型:xgboost
作用:分数超过设定阈值且是Top1作为最终候选
要求:正类准确率高
特征:
- 局部特征
- 切词变化:短语个数、含错别字片段长度等
- PMI变化:最小值、最值
- 频次变化:频次变化、2gram频次变化
- 4gram语言模型变化
- 形音变化:拼音韵母变化、jccard距离、五笔变化
- 其他:停用词\错别字位置、候选来源等等
- 全局特征
- Cbow-LM
- LSTM-Attention-LM
- BERT-LM
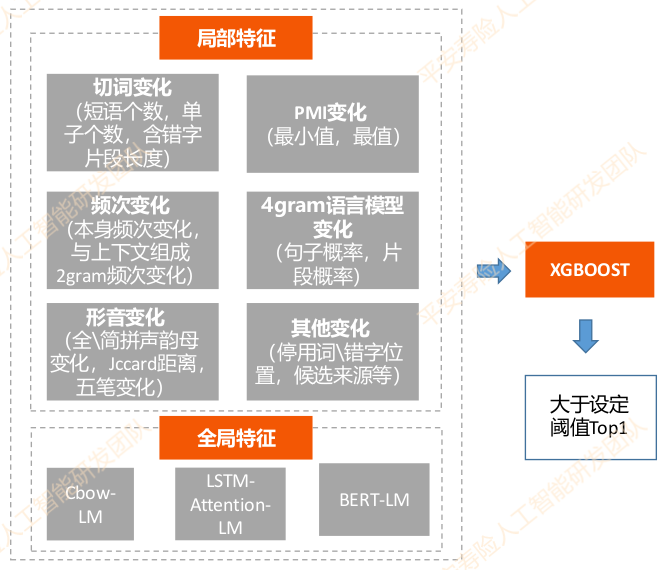
例子:==红癍狼仓==常见症状有哪些? ==红斑狼疮==
- 频次 :20 -> 1688
- 切词:红\癍\狼疮 (1\1\2) -> 红斑狼疮 (4)
- nn语言模型:癍 (<0.001) -> 斑 (0.979)
- 4gram语言模型:-19.2 -> -10.6
- PMI:红癍(0.33) ->红斑(9.7)
- 局部特征
3.4 整体架构
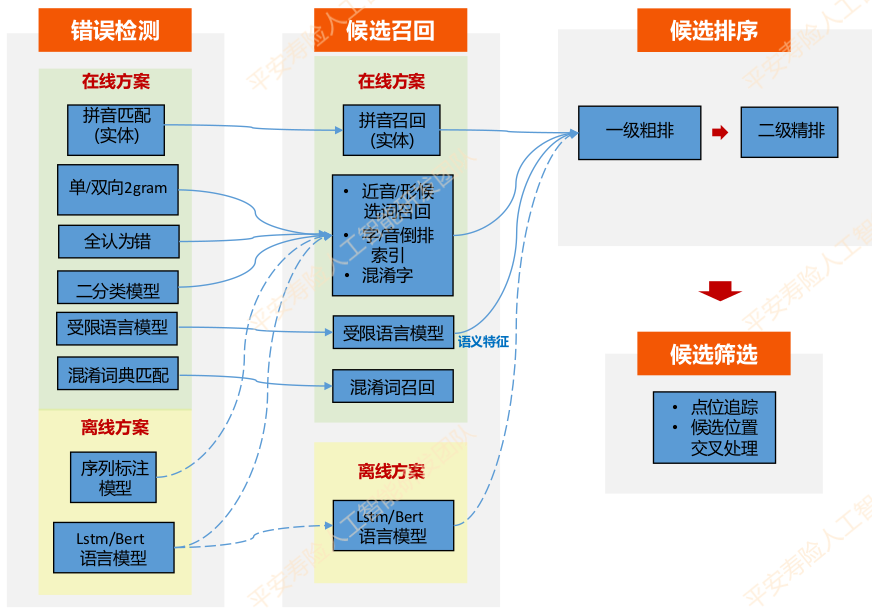
特性:
pipline串联,热插拔
子模块均遵循检测-召回-排序流程
规则+模型混用
离线+在线
在线方案:
- 低延迟、低复杂度
- 高速1ms-3ms/句
- 用于线上实时预测
离线方案:
- 大规模、复杂模型
- 低速200ms-500ms/句
- 用于构造在线模型,训练数据
3.5 总结与改进
- 优点:
- 无监督,方便将该方法迁移到其他垂直领域,只需要重新无监督挖掘数据
- 系统架构方便插拔特殊编写纠错子模块
- 缺点:
- 很难迁移到通用领域
- Pipline导致错误逐级传递
- Pipline链越长,耗时越长
- 改进思路
- 强化上下文/全局的语义理解
- 训练预料去噪处理
- 端到端算法,如NMT(神经机器翻译)
- 语法错误(多字少字乱序)
4. 爱奇艺文本纠错方案
《FASPell: A Fast, Adaptable, Simple, Powerful Chinese Spell Checker Based On DAE-Decoder Paradigm》
4.1 背景
大部分的中文拼写检查模型都使用用一个范式,即讲每个汉字的固定相似字符集(混淆集或困惑集)作为候选项,然后使用过滤器选择最佳候选项作为错字的替换字符。这种设计面临着两个主要瓶颈:
稀疏的中文拼写检查数据上的过拟合问题。
由于中文拼写检查数据需要乏味繁冗的专业人力工作,因为一直资源不足。为了防止模型的过拟合, Wang等人(2018)提出了一种自动方法来生成伪拼写检查数据。 但是,当生成的数据达到40k句子时,其拼写检查模型的精度不再提高。 Zhao等人(2017)使用了大量的语言学规则来过滤候选项,但结果却比我们的表现差,尽管我们的模型没有利用任何语言学知识。
困惑集的使用带来的汉字字符相似度利用上的不灵活性和不充分性问题。
困惑集因为是固定的,因此并非在任何语境、场景下都能包含正确候选项(一个比较极端的例子是,如果困惑集按照繁体中文制定,那么繁体中文的 “體”和“休”肯定不在困惑集的同一组相似字符中,但是在简体中文中对应的“体”和“休”缺是相似字符,如果错误文本中是把“休”写成了“体”,那么繁体中文困惑集下就无法检出,必须专门再制定一个简体困惑集才可以),这会极大降低检测的召回率(不灵活性问题);另外,困惑集中的字符的相似性的信息有损失,没有得到充分利用,因为一个字符在困惑集中相似字符是无差别对待的,然而事实上每两个字符间的相似度明显是有差别的,因此会影响检测的精确率(不充分性)。
4.2 设计
FASPell提出通过设计中文拼写检查范式来避免传统模型的两个瓶颈。FASPell利用seq2seq的思想,包括去噪自编码器(DAE)和解码器。
编码器DAE
DAE通过利用无监督预训练方法(BERT),减少了监督学习中所需的中文拼写检查数据量(<10000个句子)。DAE可以将错误文本修改为正确文本的可能候选矩阵,解码器只需要在这个矩阵中寻求最佳候选项作为输出。DAE因为可以在大规模正常预料数据上无监督训练,而仅在中文拼写检测数据上做fine-tune,避免了过拟合问题。此外,只要DAE足够强大,所有语境上可能的候选字符都可以出现,且候选字符是根据上下文即时生成的,避免了困惑集带来的不灵活性。
解码器CSD
CSD巧妙的将预训练模型的置信度和字相似度结合起来,作为候选集的评价标准,消除困惑集的使用。CSD根据量化的字符相似度和DAE给出的符合语境的置信度来过滤出正确的替换字符,如此,字符相似性上的细微差别信息都可以得到充分利用。
模型架构如图1所示:
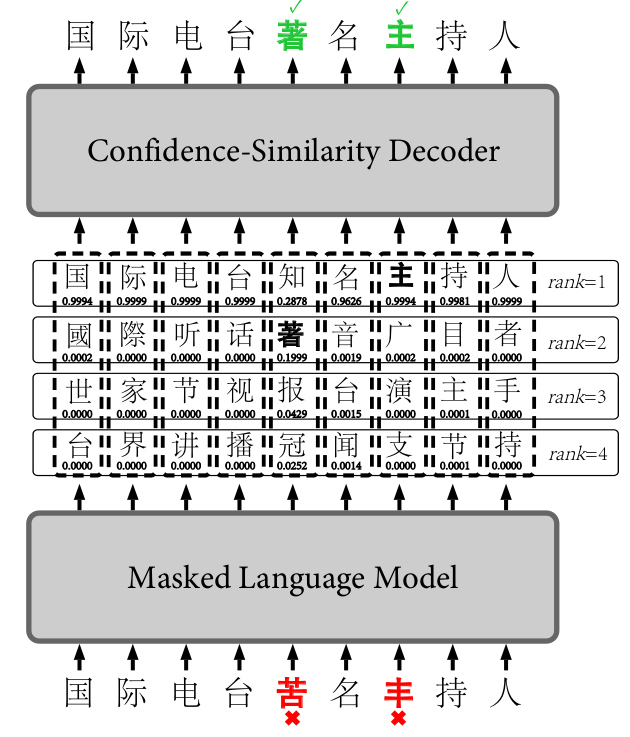
可以看到,在FASPell中,DAE由BERT中的掩码语言模型(MLM)来充当,而解码器使用了置信度-相似度解码器(CSD)。
4.3 CSD解码器
CSD主要结合DAE的置信度和字符相似度,置信度直接由DAE给出,暂且不谈,这里详细说明字符相似度。
字符相似度
字音
采用中日韩统一表意文字(CJK)语言中的汉语发音,尽管目前只是对中文文本检错纠错,但是实验证明考虑诸如粤语、日语音读、韩语、越南语的汉字发音对提高拼写检查的性能是有帮助的,而过去的方法均只考虑了普通话拼音。
字形
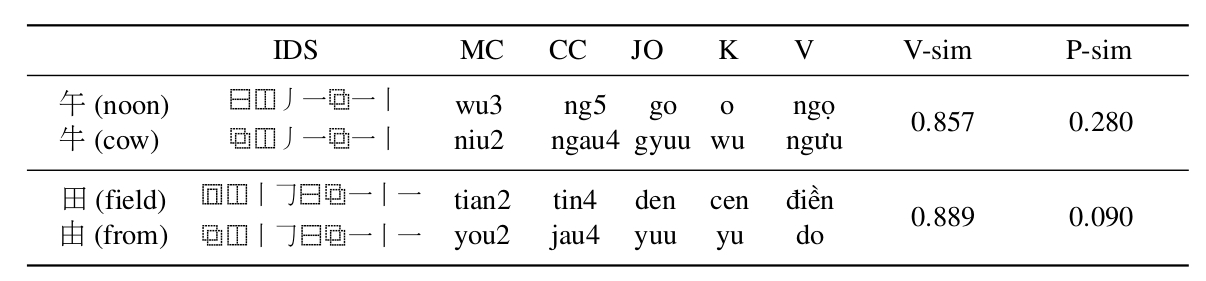
采用Unicode标准的IDS表征,它可以准确的扫描汉字中各个笔画和他们的布局方式,这使得即使相同笔画和笔画顺序的汉字之间也拥有不为1的相似度。
以午和牛,田和由为例:
训练CSD
CSD的训练阶段,利用训练集文本通过MLM输出的矩阵,逐行绘制置信度-字符相似度散点图,确定能将FP和 TP分开的最佳分界曲线。
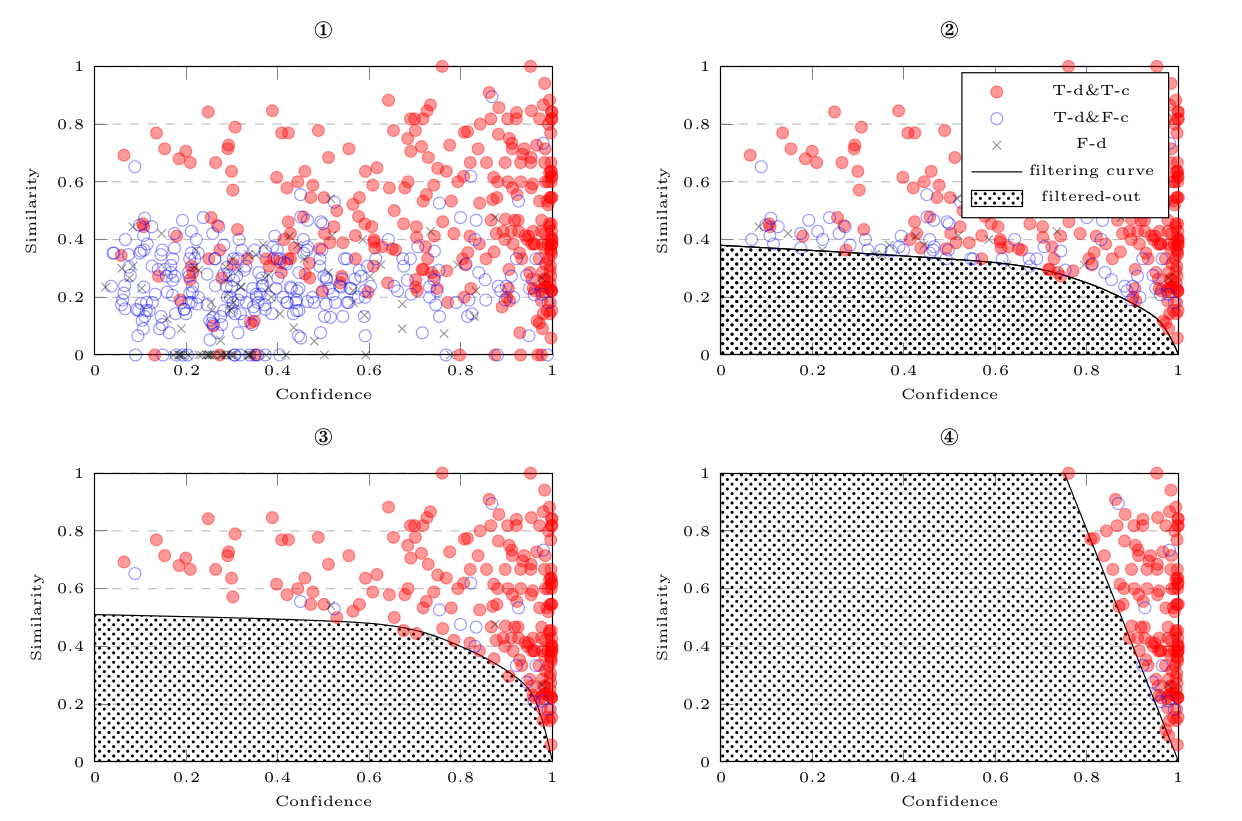
如上图所示,红点代表正确检测并正确纠正的样本,蓝色圆圈代表正确检测但纠正错误的样本,叉叉代表错误检测的样本。图一并没有过滤候选集;图二倾向于错误检测性能,大部分正确检测的候选集保留了下来;图三更加倾向于错误纠正,FASPell采用此种曲线;图四采用加权确定阈值的方式来确定曲线$(0.8×confidence+0.2×similarity<0.8)$。
在训练阶段,我们的目标在于确定一条合适的曲线,供于推理阶段使用。
推理
在推理阶段,逐行根据分界线过滤掉FP得到TP结果,然后将每行的结果取并集得到最终替换结果。以上面架构图为例片,句子首先通过fine-tune训练好的MLM模型,得到的候选字符矩阵通过CSD进行解码过滤,第一行候选项中只有“主”字没有被CSD过滤掉,第二行只有“著”字未被过滤掉,其它行候选项均被分界线过滤清除,得到最终输出结果,即“苦”字被替换为为“著”,“丰”被替换为“主”。
信息熵
一. 熵
解释
- 熵是不确定的度量
- 熵是信息的度量
计算公式
$$
S = - \sum _{x} p(x)\log p(x) \tag{1}
$$log可以取自然对数,也可以是以底为2的对数,任意大于1的底都是成立的。换底只不过换了信息的单位而已。
对于连续的概率分布,熵的定义为:
$$
S=- \int p(x) \log p (x)dx \tag{2}
$$
联合熵
$$
S[p(x,y)]=-\sum_{x} \sum_{y}p(x,y)\ln p(x,y) \tag{3}
$$条件熵
$$
S(Y|X)=S[p(x,y)] - S[p(x)] \tag{4}
$$
等价于:
$$
S(Y|X)=-\sum_{x} \sum_{y}p(x,y) \log p(y:x) \tag{5}
$$
通俗的说,本来的信息量有$$S[p(x,y)]$$ ,然后$$p(x)$$ 能带来$$S[p(x)]$$ 的信息,减去其不确定性,剩下的就是条件熵。互信息
互信息可以度量两个随机事件“相关性”的量化
$$
S(X;Y)=\sum_{x}\sum_{y}p(x,y)\log \frac{p(x,y)}{p(x)p(y)} \tag{6}
$$互信息就是随机事件X,以及知道随机事件Y条件下的不确定性,或者条件熵之间的差异。即。
$$
S(X;Y)=S(X) -S(X|Y) \tag{7}
$$相对熵
相对熵也是来衡量相关性,但和互信息不同,它用来衡量两个取值为正数的函数的相似性。
$$
KL(f(x)||g(x))=\sum_{x \in X}f(x)\cdot \log \frac {f(x)}{g(x)} \tag{8}
$$- 对于两个完全相同的函数,他们的相对数为0
- 相对熵越大,两个函数差异越大;反之,相对熵越小,两函数差异越小
- 对于概率分布和概率密度分布,如果取值均大于0,相对熵可以度量两个随机分布的差异性
相对熵是不对称的。
$$
KL(f(x)||g(x)) \ne KL(g(x)||f(x)) \tag{9}
$$
詹森和香农提出了一种相对熵的计算方法,将上面的不等式变为等式。
$$
JS(f(x)||g(x))=\frac{1}{2}[KL(f(x)||g(x))+KL(g(x)||f(x))] \tag{10}
$$
二. 最大熵
当我们想要得到一个随机事件的概率分布时,如果没有足够的信息能够确定这个概率分布(可能是不能确定分布,也可能是知道分布的类型,但是还有若干个参数没有确定),那么最“保险”的方案就是选择使得熵最大的分布。
常见安装脚本
1. 安装python3.6.5
安装依赖包
centos
1
yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel libffi-devel
ubuntu
1
sudo apt-get install zlib1g-dev libbz2-dev libssl-dev libncurses5-dev libsqlite3-dev libreadline-dev tk-dev libgdbm-dev libdb-dev libpcap-dev xz-utils libexpat1-dev liblzma-dev libffi-dev libc6-dev
解压
安装
1
2./configure
make && make install添加软连接
1
2ln -s /usr/local/python3/bin/python3.6.7 /usr/bin/python3
ln -s /usr/local/python3/bin/pip3.6.5 /usr/bin/pip3
2. 安装neo4j
neo4j底层依赖java,请自行安装jdk
下载neo4j
解压
配置neo4j.conf文件,修改相应配置(配置行数针对3.4.5版本,其他版本自行寻找相应配置)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38修改第22行load csv时l路径,在前面加个#,可从任意路径读取文件
dbms.directories.import=import
修改35行和36行,设置JVM初始堆内存和JVM最大堆内存
生产环境给的JVM最大堆内存越大越好,但是要小于机器的物理内存
dbms.memory.heap.initial_size=5g
dbms.memory.heap.max_size=10g
修改46行,可以认为这个是缓存,如果机器配置高,这个越大越好
dbms.memory.pagecache.size=10g
修改54行,去掉改行的#,可以远程通过ip访问neo4j数据库
dbms.connectors.default_listen_address=0.0.0.0
默认 bolt端口是7687,http端口是7474,https关口是7473,不修改下面3项也可以
修改71行,去掉#,设置http端口为7687,端口可以自定义,只要不和其他端口冲突就行
dbms.connector.bolt.listen_address=:7687
修改75行,去掉#,设置http端口为7474,端口可以自定义,只要不和其他端口冲突就行
dbms.connector.http.listen_address=:7474
修改79行,去掉#,设置http端口为7473,端口可以自定义,只要不和其他端口冲突就行
dbms.connector.https.listen_address=:7473
修改227行,去掉#,允许从远程url来load csv
dbms.security.allow_csv_import_from_file_urls=true
修改246行,允许使用neo4j-shell,类似于mysql 命令行之类的
dbms.shell.enabled=true
修改235行,去掉#,设置连接neo4j-shell的端口,一般都是localhost或者127.0.0.1,这样安全,其他地址的话,一般使用https就行
dbms.shell.host=127.0.0.1
修改250行,去掉#,设置neo4j-shell端口,端口可以自定义,只要不和其他端口冲突就行
dbms.shell.port=1337
修改254行,设置neo4j可读可写
dbms.read_only=false启动,进入neo4j目录。
1
./bin/neo4j start
Active database: graph.db
Directories in use:
home: /root/neo4j-community-3.4.5
config: /root/neo4j-community-3.4.5/conf
logs: /root/neo4j-community-3.4.5/logs
plugins: /root/neo4j-community-3.4.5/plugins
import: NOT SET
data: /root/neo4j-community-3.4.5/data
certificates: /root/neo4j-community-3.4.5/certificates
run: /root/neo4j-community-3.4.5/run
Starting Neo4j.
Started neo4j (pid 19029). It is available at http://0.0.0.0:7474/
There may be a short delay until the server is ready.
See /root/neo4j-community-3.4.5/logs/neo4j.log for current status.停止
1
bin/neo4j stop
Stopping Neo4j.. stopped
情感分析总结
1. last3embedding
参考:https://blog.csdn.net/weixin_45839693/article/details/109378849
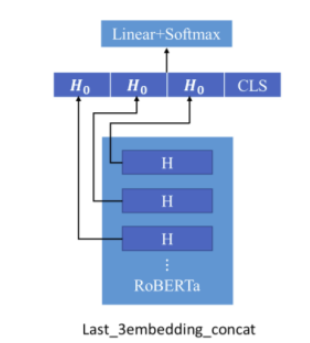
模型比较简单,就是将最后3层的cls取出来拼接在一起,接dense即可。
1 | def forward(self, inputs): |
改进:
接lstm
接textcnn
预训练模型梳理
summary Table
| 模型 | 语言模型 | 特征抽取 | 上下文表征 | 亮点 |
|---|---|---|---|---|
| ELMO | BiLM | Bi-LSTM | 单向 | 2个单向语言模型拼接 |
| ULMFiT | LM | AWD-LSTM | 单向 | 引入逐层解冻fine-tune中的灾难性问题 |
| SiATL | LM | LSTM | 单向 | 引入逐层解冻+辅助LM解决fine-tune中的灾难性问题 |
| GPT1.0 | LM | Transformer | 单向 | 统一下游任务框架,验证Transformer在LM中的强大 |
| GPT2.0 | LM | Transformer | 单向 | 没有特定的fine-tune流程,生成任务取得好的结果 |
| BERT | MLM | Transformer | 双向 | MLM获取上下文相关的双向特征表示 |
| MASS | LM+MLM | Transformer | 单向/双向 | 改进BERT生成任务:统一为类seq2seq的预训练模型 |
| UNILM | LM+MLM+S2SLM | Transformer | 单向/双向 | 改进BERT生成任务,直接从mask矩阵的角度出发 |
| ENRIE1.0 | MLM(BPE) | Transformer | 双向 | 引入知识:3种MASK策略(BPE)预测短语和实体 |
| ENRIE | MLM+DEA | Transformer | 双向 | 引入知识:讲实体向量和文本表示相融合 |
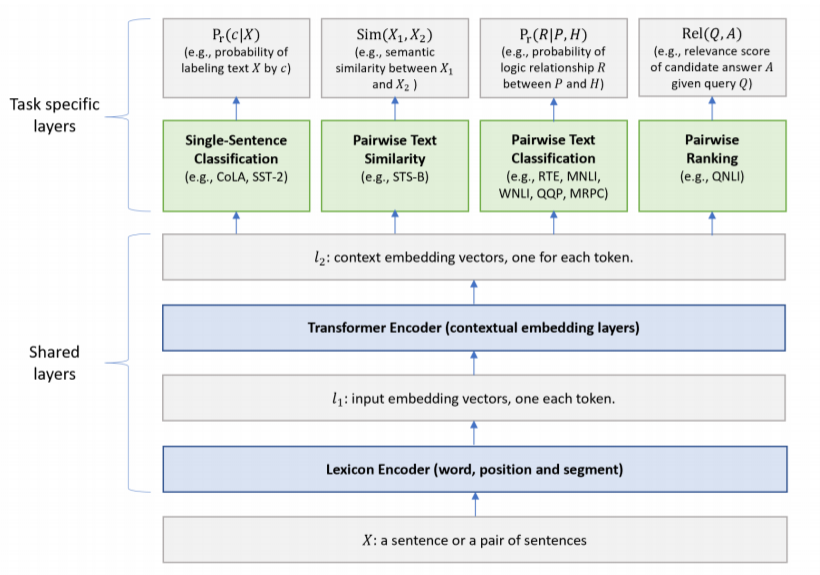
| MTDNN | MLM | Transformer | 双向 | 引入多任务学习:在下游阶段 |
| ENRIE2.0 | MLM+Multi-Task | Transformer | 双向 | 引入多任务学习:在预训练阶段,连续增量学习 |
| SpanBERT | MLM+SPO | Transformer | 双向 | 不需要按照边界信息进行mask |
| RoBERTa | MLM | Transformer | 双向 | 精细调参,舍弃NSP |
| XLNet | PLM | Transformer-XL | 双向 | 排列语言模型+双注意力机制+Transformer |
1. word2vec
2. ELMo
要点
- 引入双向语言模型,2个单向的语言模型(向前和向后)的集成。
- 通过保存预训练好的2层BiLSTM,通过特征集成或finetune应用于下游任务。
缺陷
- 本质上是自回归语言模型,只能获取单向特征表示,不能同时获取上下文。
- LSTM不能解决长距离依赖问题。
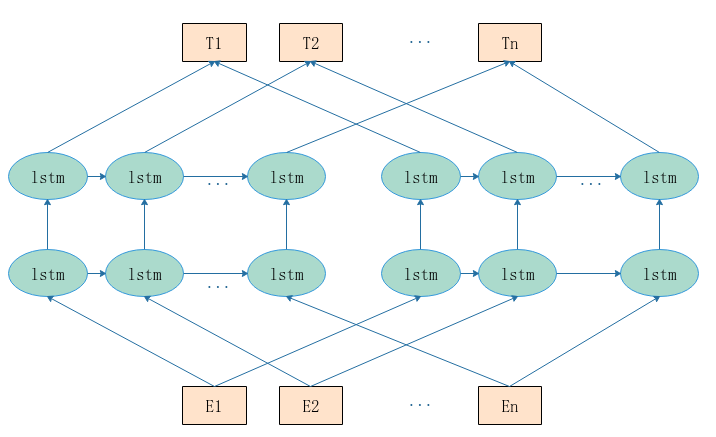
为什么不能用BiLSTM构建双向语言模型
如果采用BiLSTM构建双向语言模型,会造成标签泄露的问题。因此ELMo前向和后向的LSTM参数独立,共享词向量,拼接构造语言模型。
3. GPT1.0/GPT2.0(OpenAI)
GPT1.0要点
相比ELMo,将LSTM替换成了transformer,首次将Transformer应用与预训练模型。
finetune阶段引入语言模型辅助目标,解决finetune过程中的灾难性遗忘问题。
GPT2.0要点
- 不针对特定模型的精调过程:GPT2.0认为预训练中已经包含了许多特定任务所需的信息。
- 生成式任务效果比较好,使用了覆盖更广、质量更好的数据。
缺点
- 依然为单向的自回归语言模型,没有编码上下文的特征表示。
4. BERT(重点介绍)
Transformer
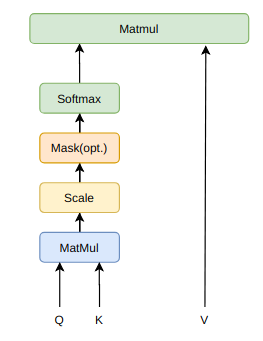
$ Attention(Q,K,V) = softmax(\frac{QK^{T}}{\sqrt{d_{k}}})V$
Multi-Head Attention和Scaled Dot-Product Attention
本质上是self attention通过attention mask动态编码变长序列,解决长依赖、无位置偏差、可并行计算。
为什么是缩放点积,而不是点积模型?
当输入信息的维度较高时,点积模型的值通常有较大方差,从而导致softmax函数的梯度较小,因此缩放点积模型可以较好的解决这一问题。
为什么是双线性点积模型(经过线性变换$Q \ne K$)?
双线性点积模型,引入非对称性,根据健壮性(Attention mask对角线元素不一定是最大的,也就是说当前位置对自身的注意力得分不一定最高)。
相较与加性模型,点积模型具备哪些优势?
常用的attention机制有加性模型和点积模型,理论上两者的复杂度差不多,但是点积模型在实现上可以更好的利用矩阵乘积,从而效率更高。
多头机制为什么有效?
- 类似于CNN中的通过多通道机制进行特征选择
- Transformer中先通过切头(split),再分别进行Scale-Product Attention,可以使进行点积计算的维度d不会太大,同时缩小attention mask矩阵。
Position-wise Feed-Forward Networks
- FFN将每个位置的Multi-Head Attention结果隐射到一个更大的特征空间,然后使用ReLU引入非线性进行筛选,最后恢复原始维度。
- Transformer放弃LSTM之后,FFN中的ReLU成为了一个主要的提供非线性变换的单元。
Positional Encoding
Position Encoding是可学习的,编码范围不受限制。
$$PE_{(pos,2i)}=sin(pos/10000^{2i/d_{model}})$$
$$PE_{(pos,2i+1)}=cos(pos/10000^{2i/d_{model}})$$
- 为什么引入$sin$和$cos$建模Position Encoding?
- 为了使得模型实现相对位置的学习,两个位置pos和pos+k的位置编码是固定间距k的线性变化。
- 可以证明,间隔为k的任意两个位置编码的欧式距离是恒等的,只与k有关。
- 为什么引入$sin$和$cos$建模Position Encoding?
BERT为什么如此有效?
- 引入Masked Language Model(MLM)预训练目标,能够获取上下文相关的双向特征表示
- 引入Next Sentence Prediction(NSP)预训练目标,擅长处理句子或段落的匹配任务。
- 引入强大的特征抽取机制。
- Muti-Head self attention:多头机制类似于多通道特征抽取
- self attention通过attention mask动态编码变长序列,解决长距离依赖、可并行计算
- Feed-forward :非线性层级特征
- Layer Norm & Residuals:加速训练,使深度网络更加健壮。
- BERT 通过不同的迁移学习应用与下游任务,BERT擅长处理NLU任务。
- BERT通过MLM解决了深层BiLSTM构建双向模型中存在的‘标签泄露’问题,也就是‘see itself’。
BERT的优缺点?
- 优点:能够获取上下文相关的双向特征表示
- 缺点:
- 生成任务表现不佳
- 采取独立性假设:没有考虑预测[MASK]之间的相关性,是对语言模型联合概率的有偏估计(不是密度估计)。
- 输入噪声[MASJ],造成预训练-finetune两阶段之间的差异。
- 无法处理文档级别的NLP任务,只适合句子和段落级别的任务。
BERT基于‘字输入’还是‘词输入’好?(中文)
- 如果基于’词输入‘,可能会出现’OOV‘问题,增大标签空间,需要利用更多预料去学习标签分布来拟合模型
- 随着Transformer特征抽取能力加强,分词不再成为必要,词级别的特征学习可以纳入内部特征进行表示学习。
5. BERT改进系列模型
5.1 改进生成任务
MASS

统一预训练框架:通过类似于Seq2Seq的框架,在预训练阶段统一了BERT和LM模型
Encoder中理解unmasked tokens;Decoder中需要预测连续的[mask]tokens,获取更多的语言信息;Decoder从Encoder中抽取更多信息
当k=1或者n时,MASS的概率形式分别和BERT中的MLM以及GPT中标准的LM一致(k为mask的连续片段长度)
UNILM
- 统一预训练模型框架:直接从mask矩阵角度统一BERT和LM
- 3个Attention Mask矩阵:LM、MLM、Seq2Seq LM
- UNILM中的LM并不是传统的LM模型,任需通过引入[MASK]实现。
5.2 引入知识
ERNIE1.0(百度)
在预训练阶段引入知识(预先识别出的实体),引入三种[MASK]策略
- Basci-Level Masking:和BERT一样,对subword进行mask,无法获取高层次的语义。
- Phrase-Level Masking:mask连续短语。
- Entity-Level Masking:mask实体。
ERNIE(THU)
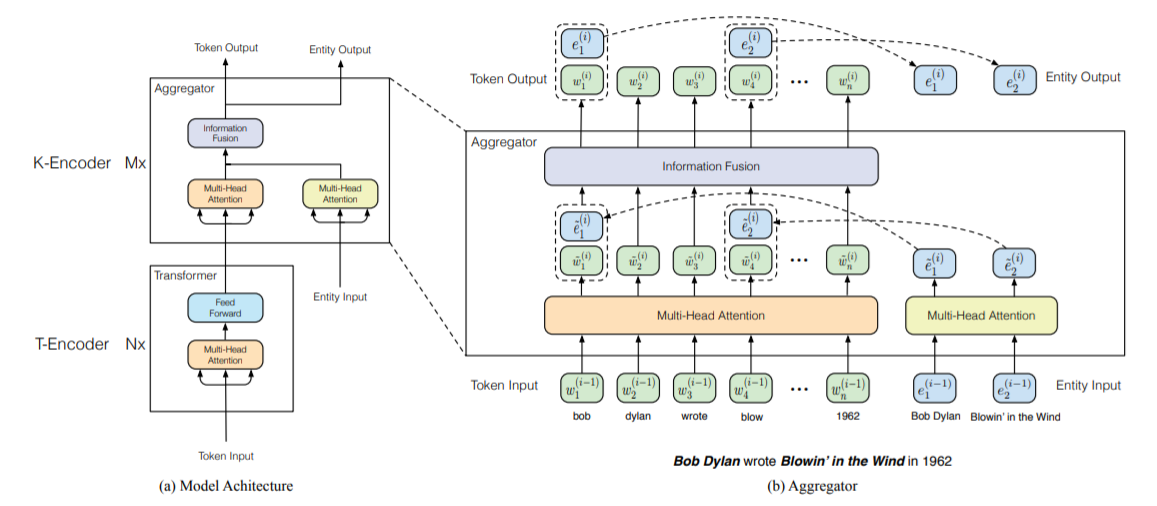
- 基于BERT预训练原生模型,讲文本中的实体对齐到外部的知识图谱,并通过知识嵌入得到实体向量作为ERNIR的输入。
- 由于语言表征的预训练过程和知识表征过程有很大的不同,会产生两个独立的向量空间,为解决这个问题,在有实体输入的位置,将实体向量和文本表示通过非线性变换进行融合,以融合词汇、句法和知识信息。
- 引入改进的预训练目标Denoising entity auto-encoder(DEA):要求模型能够根据给定的实体序列和文本序列来预测对应的实体。
5.3 引入多任务机制
多任务学习是指同时学习多个相关任务,让这些任务在学习过程中共享知识,利用多个任务之间的相关性来改善模型在每个任务的性能和泛华能力。
MTDNN(微软):在下游任务中引入多任务学习机制
ERNIE 2.0(百度)
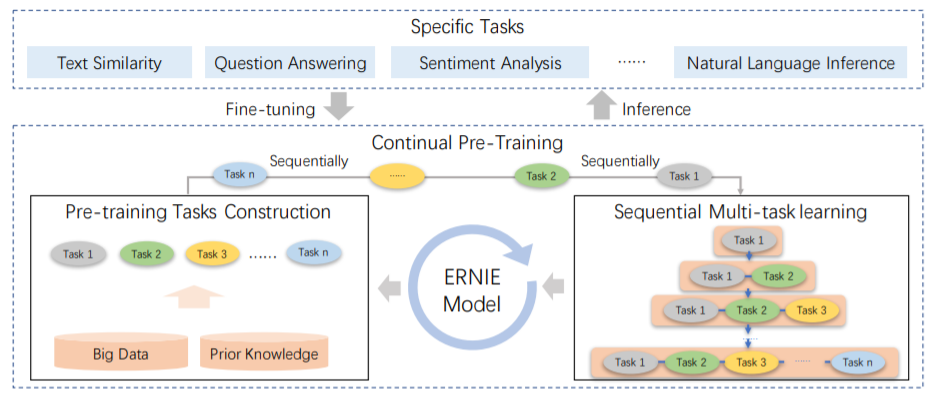
- MTDNN是在下游任务引入多任务机制的,而ERNIE2.0是在预训练引入多任务学习(与先验知识库进行交互),使模型能够从不同的任务中学到更多的语言知识。
- 构建多个层次的任务全面捕捉训练预料中的词法、结构、语义的潜在知识。主要包含3个方面的任务:
- 词法层面,word-aware任务:捕捉词汇层面的信息,如英文大小写预测。
- 结构层面,structure-aware任务:捕捉句法层次的信息,如句子顺序问题、句子距离问题。
- 语义层面,semantic-aware任务:捕捉语义方面的问题,如语义逻辑关系预测(因果,假设,递进,转折)。
- 主要的方式是构建增量学习模型,通过多任务学习持续更新预训练模型,这种连续交替的学习范式不会使模型忘记之前学到的语言知识。
5.4 改进mask策略
原生BERT模型:按照subword维度进行mask,然后预测,局部的语言模型,缺乏全局建模的能力。
- BERT WWM(google):进行whole word维度进行mask。
- ERNIE系列:建模词、短语、实体的完整语义:通过先验知识将知识(短语、词、实体)进行整体mask;引入外部知识,按照entity维度进行mask,然后进行预测。
- Span Bert:不需要按照先验的词、实体、短语等边界信息进行mask,而是采取随机mask
- 采用Span Masking:根据几何分布,随机选择一段空间长度,之后再根据均匀分布随机选择起始位置,最后按照长度mask,通过采样,平均被遮盖长度是3.8个词的长度。
- 引入Span Boundary Objective:新的预训练目标旨在使被mask的Span 边界的词向量能学习到 Span中被mask的部分;新的预训练目标和MLM一起使用;
5.5 精调
- RoBERTa(FaceBook)
- 丢弃NSP,效果更好
- 动态改变mask策略,把数据复制10份,然后统一进行随机mask
- 对学习率的峰值和warm-up跟新步数做出调整
- 在更长序列上训练,不对序列进行截断,使用全长度序列
6. XLNet
6.1 提出的背景
- 对于ELMO、GPT等预训练模型都是基于传统的语言模型(自回归语言模型AR),自回归语言模型天然适合处理生成任务,但是无法对双向上下文进行表征。
- 自编码语言模型(AE)虽然可以实现双向上下文表征,但是:
- BERT系列模型引入独立性假设,没有考虑预测[mask]之间的相关性。
- MLM预训练目标的设置造成预训练过程和生成过程不一致。
- 预训练时的[mask]噪声在finetune阶段不会出现,造成两阶段不匹配问题。
6.2 核心机制分析
- 使用自回归语言模型,为解决双向上下文问题,引入了排列语言模型PLM
- PLM在预测时需要target的位置信息,此为引入了Two-Stream:Content流编码到当前时刻的所有内容,而Query流只能参考之前的历史信息以及当前要预测的位置信息。
- 为解决计算量过大的问题,采取随机采样语言排列+只预测1个句子后面的1/k的词。
- 融合Transformer-XL的优点处理长文本。
排列语言模型(Permutation LM,PLM)
Two-Stream Self-Attention
融入Transformer-XL