summary Table
| 模型 | 语言模型 | 特征抽取 | 上下文表征 | 亮点 |
|---|---|---|---|---|
| ELMO | BiLM | Bi-LSTM | 单向 | 2个单向语言模型拼接 |
| ULMFiT | LM | AWD-LSTM | 单向 | 引入逐层解冻fine-tune中的灾难性问题 |
| SiATL | LM | LSTM | 单向 | 引入逐层解冻+辅助LM解决fine-tune中的灾难性问题 |
| GPT1.0 | LM | Transformer | 单向 | 统一下游任务框架,验证Transformer在LM中的强大 |
| GPT2.0 | LM | Transformer | 单向 | 没有特定的fine-tune流程,生成任务取得好的结果 |
| BERT | MLM | Transformer | 双向 | MLM获取上下文相关的双向特征表示 |
| MASS | LM+MLM | Transformer | 单向/双向 | 改进BERT生成任务:统一为类seq2seq的预训练模型 |
| UNILM | LM+MLM+S2SLM | Transformer | 单向/双向 | 改进BERT生成任务,直接从mask矩阵的角度出发 |
| ENRIE1.0 | MLM(BPE) | Transformer | 双向 | 引入知识:3种MASK策略(BPE)预测短语和实体 |
| ENRIE | MLM+DEA | Transformer | 双向 | 引入知识:讲实体向量和文本表示相融合 |
| MTDNN | MLM | Transformer | 双向 | 引入多任务学习:在下游阶段 |
| ENRIE2.0 | MLM+Multi-Task | Transformer | 双向 | 引入多任务学习:在预训练阶段,连续增量学习 |
| SpanBERT | MLM+SPO | Transformer | 双向 | 不需要按照边界信息进行mask |
| RoBERTa | MLM | Transformer | 双向 | 精细调参,舍弃NSP |
| XLNet | PLM | Transformer-XL | 双向 | 排列语言模型+双注意力机制+Transformer |
1. word2vec
2. ELMo
要点
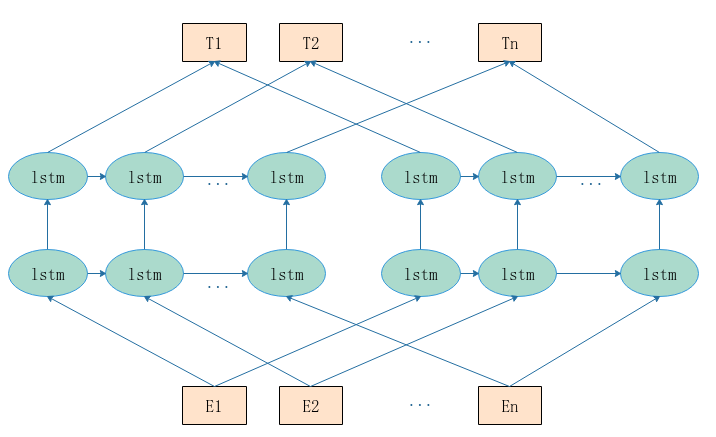
- 引入双向语言模型,2个单向的语言模型(向前和向后)的集成。
- 通过保存预训练好的2层BiLSTM,通过特征集成或finetune应用于下游任务。
缺陷
- 本质上是自回归语言模型,只能获取单向特征表示,不能同时获取上下文。
- LSTM不能解决长距离依赖问题。
为什么不能用BiLSTM构建双向语言模型
如果采用BiLSTM构建双向语言模型,会造成标签泄露的问题。因此ELMo前向和后向的LSTM参数独立,共享词向量,拼接构造语言模型。
3. GPT1.0/GPT2.0(OpenAI)
GPT1.0要点
相比ELMo,将LSTM替换成了transformer,首次将Transformer应用与预训练模型。
finetune阶段引入语言模型辅助目标,解决finetune过程中的灾难性遗忘问题。
GPT2.0要点
- 不针对特定模型的精调过程:GPT2.0认为预训练中已经包含了许多特定任务所需的信息。
- 生成式任务效果比较好,使用了覆盖更广、质量更好的数据。
缺点
- 依然为单向的自回归语言模型,没有编码上下文的特征表示。
4. BERT(重点介绍)
Transformer
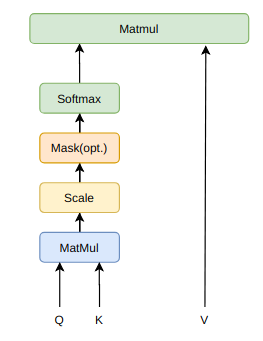
$ Attention(Q,K,V) = softmax(\frac{QK^{T}}{\sqrt{d_{k}}})V$
Multi-Head Attention和Scaled Dot-Product Attention
本质上是self attention通过attention mask动态编码变长序列,解决长依赖、无位置偏差、可并行计算。
为什么是缩放点积,而不是点积模型?
当输入信息的维度较高时,点积模型的值通常有较大方差,从而导致softmax函数的梯度较小,因此缩放点积模型可以较好的解决这一问题。
为什么是双线性点积模型(经过线性变换$Q \ne K$)?
双线性点积模型,引入非对称性,根据健壮性(Attention mask对角线元素不一定是最大的,也就是说当前位置对自身的注意力得分不一定最高)。
相较与加性模型,点积模型具备哪些优势?
常用的attention机制有加性模型和点积模型,理论上两者的复杂度差不多,但是点积模型在实现上可以更好的利用矩阵乘积,从而效率更高。
多头机制为什么有效?
- 类似于CNN中的通过多通道机制进行特征选择
- Transformer中先通过切头(split),再分别进行Scale-Product Attention,可以使进行点积计算的维度d不会太大,同时缩小attention mask矩阵。
Position-wise Feed-Forward Networks
- FFN将每个位置的Multi-Head Attention结果隐射到一个更大的特征空间,然后使用ReLU引入非线性进行筛选,最后恢复原始维度。
- Transformer放弃LSTM之后,FFN中的ReLU成为了一个主要的提供非线性变换的单元。
Positional Encoding
Position Encoding是可学习的,编码范围不受限制。
$$PE_{(pos,2i)}=sin(pos/10000^{2i/d_{model}})$$
$$PE_{(pos,2i+1)}=cos(pos/10000^{2i/d_{model}})$$
- 为什么引入$sin$和$cos$建模Position Encoding?
- 为了使得模型实现相对位置的学习,两个位置pos和pos+k的位置编码是固定间距k的线性变化。
- 可以证明,间隔为k的任意两个位置编码的欧式距离是恒等的,只与k有关。
- 为什么引入$sin$和$cos$建模Position Encoding?
BERT为什么如此有效?
- 引入Masked Language Model(MLM)预训练目标,能够获取上下文相关的双向特征表示
- 引入Next Sentence Prediction(NSP)预训练目标,擅长处理句子或段落的匹配任务。
- 引入强大的特征抽取机制。
- Muti-Head self attention:多头机制类似于多通道特征抽取
- self attention通过attention mask动态编码变长序列,解决长距离依赖、可并行计算
- Feed-forward :非线性层级特征
- Layer Norm & Residuals:加速训练,使深度网络更加健壮。
- BERT 通过不同的迁移学习应用与下游任务,BERT擅长处理NLU任务。
- BERT通过MLM解决了深层BiLSTM构建双向模型中存在的‘标签泄露’问题,也就是‘see itself’。
BERT的优缺点?
- 优点:能够获取上下文相关的双向特征表示
- 缺点:
- 生成任务表现不佳
- 采取独立性假设:没有考虑预测[MASK]之间的相关性,是对语言模型联合概率的有偏估计(不是密度估计)。
- 输入噪声[MASJ],造成预训练-finetune两阶段之间的差异。
- 无法处理文档级别的NLP任务,只适合句子和段落级别的任务。
BERT基于‘字输入’还是‘词输入’好?(中文)
- 如果基于’词输入‘,可能会出现’OOV‘问题,增大标签空间,需要利用更多预料去学习标签分布来拟合模型
- 随着Transformer特征抽取能力加强,分词不再成为必要,词级别的特征学习可以纳入内部特征进行表示学习。
5. BERT改进系列模型
5.1 改进生成任务
MASS

统一预训练框架:通过类似于Seq2Seq的框架,在预训练阶段统一了BERT和LM模型
Encoder中理解unmasked tokens;Decoder中需要预测连续的[mask]tokens,获取更多的语言信息;Decoder从Encoder中抽取更多信息
当k=1或者n时,MASS的概率形式分别和BERT中的MLM以及GPT中标准的LM一致(k为mask的连续片段长度)
UNILM
- 统一预训练模型框架:直接从mask矩阵角度统一BERT和LM
- 3个Attention Mask矩阵:LM、MLM、Seq2Seq LM
- UNILM中的LM并不是传统的LM模型,任需通过引入[MASK]实现。
5.2 引入知识
ERNIE1.0(百度)
在预训练阶段引入知识(预先识别出的实体),引入三种[MASK]策略
- Basci-Level Masking:和BERT一样,对subword进行mask,无法获取高层次的语义。
- Phrase-Level Masking:mask连续短语。
- Entity-Level Masking:mask实体。
ERNIE(THU)
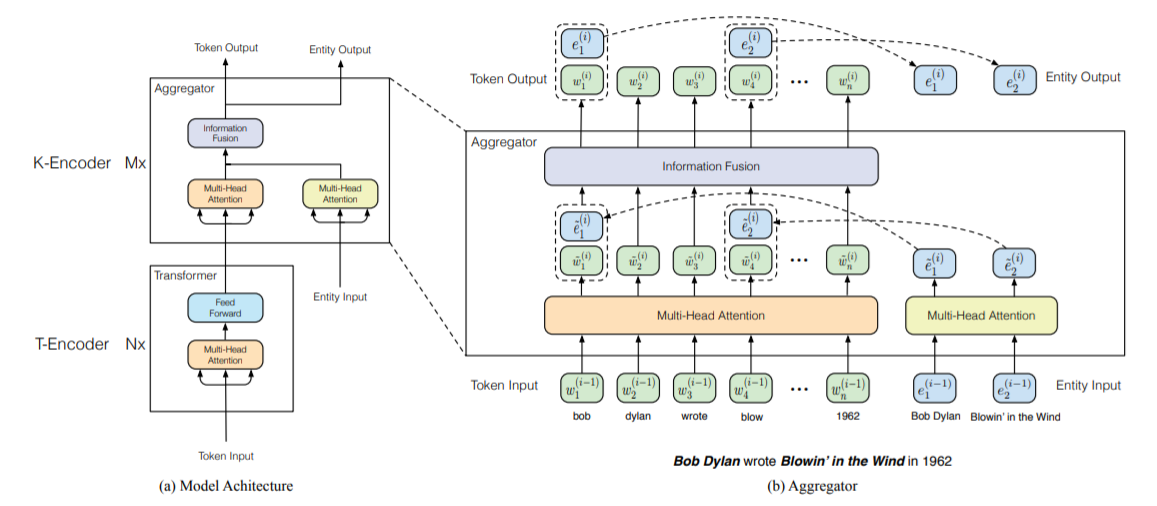
- 基于BERT预训练原生模型,讲文本中的实体对齐到外部的知识图谱,并通过知识嵌入得到实体向量作为ERNIR的输入。
- 由于语言表征的预训练过程和知识表征过程有很大的不同,会产生两个独立的向量空间,为解决这个问题,在有实体输入的位置,将实体向量和文本表示通过非线性变换进行融合,以融合词汇、句法和知识信息。
- 引入改进的预训练目标Denoising entity auto-encoder(DEA):要求模型能够根据给定的实体序列和文本序列来预测对应的实体。
5.3 引入多任务机制
多任务学习是指同时学习多个相关任务,让这些任务在学习过程中共享知识,利用多个任务之间的相关性来改善模型在每个任务的性能和泛华能力。
MTDNN(微软):在下游任务中引入多任务学习机制
ERNIE 2.0(百度)
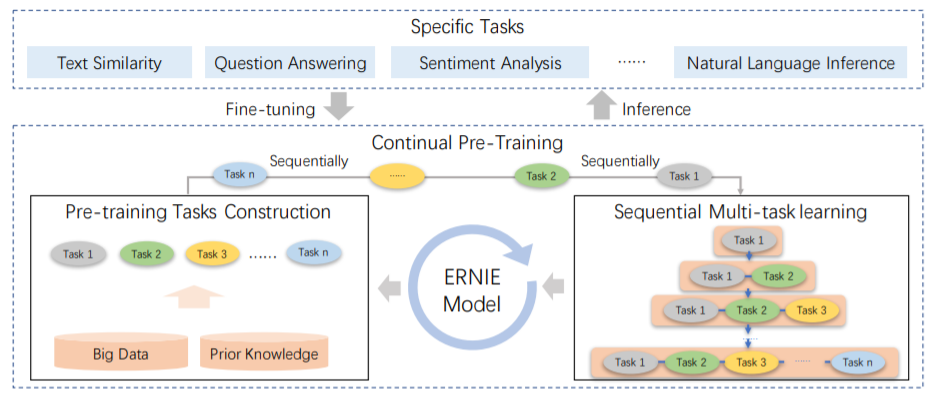
- MTDNN是在下游任务引入多任务机制的,而ERNIE2.0是在预训练引入多任务学习(与先验知识库进行交互),使模型能够从不同的任务中学到更多的语言知识。
- 构建多个层次的任务全面捕捉训练预料中的词法、结构、语义的潜在知识。主要包含3个方面的任务:
- 词法层面,word-aware任务:捕捉词汇层面的信息,如英文大小写预测。
- 结构层面,structure-aware任务:捕捉句法层次的信息,如句子顺序问题、句子距离问题。
- 语义层面,semantic-aware任务:捕捉语义方面的问题,如语义逻辑关系预测(因果,假设,递进,转折)。
- 主要的方式是构建增量学习模型,通过多任务学习持续更新预训练模型,这种连续交替的学习范式不会使模型忘记之前学到的语言知识。
5.4 改进mask策略
原生BERT模型:按照subword维度进行mask,然后预测,局部的语言模型,缺乏全局建模的能力。
- BERT WWM(google):进行whole word维度进行mask。
- ERNIE系列:建模词、短语、实体的完整语义:通过先验知识将知识(短语、词、实体)进行整体mask;引入外部知识,按照entity维度进行mask,然后进行预测。
- Span Bert:不需要按照先验的词、实体、短语等边界信息进行mask,而是采取随机mask
- 采用Span Masking:根据几何分布,随机选择一段空间长度,之后再根据均匀分布随机选择起始位置,最后按照长度mask,通过采样,平均被遮盖长度是3.8个词的长度。
- 引入Span Boundary Objective:新的预训练目标旨在使被mask的Span 边界的词向量能学习到 Span中被mask的部分;新的预训练目标和MLM一起使用;
5.5 精调
- RoBERTa(FaceBook)
- 丢弃NSP,效果更好
- 动态改变mask策略,把数据复制10份,然后统一进行随机mask
- 对学习率的峰值和warm-up跟新步数做出调整
- 在更长序列上训练,不对序列进行截断,使用全长度序列
6. XLNet
6.1 提出的背景
- 对于ELMO、GPT等预训练模型都是基于传统的语言模型(自回归语言模型AR),自回归语言模型天然适合处理生成任务,但是无法对双向上下文进行表征。
- 自编码语言模型(AE)虽然可以实现双向上下文表征,但是:
- BERT系列模型引入独立性假设,没有考虑预测[mask]之间的相关性。
- MLM预训练目标的设置造成预训练过程和生成过程不一致。
- 预训练时的[mask]噪声在finetune阶段不会出现,造成两阶段不匹配问题。
6.2 核心机制分析
- 使用自回归语言模型,为解决双向上下文问题,引入了排列语言模型PLM
- PLM在预测时需要target的位置信息,此为引入了Two-Stream:Content流编码到当前时刻的所有内容,而Query流只能参考之前的历史信息以及当前要预测的位置信息。
- 为解决计算量过大的问题,采取随机采样语言排列+只预测1个句子后面的1/k的词。
- 融合Transformer-XL的优点处理长文本。
排列语言模型(Permutation LM,PLM)
Two-Stream Self-Attention
融入Transformer-XL