实体关系抽取(Entity and Relation Extraction,ERE)是信息抽取的关键任务之一。ERE是一个级联任务,分为两个子任务:实体抽取和关系抽取。主流的抽取模式有两类:Pipline和联合抽取。
对比联合模型,Pipline的优缺点:
易于实现,实体和关系任务解耦,灵活性高,可以使用独立的数据集。
暴露偏差:关系训练输入的是gold实体,而预测时候输入的是实体模型预测的实体
实体冗余:存在大量的没有关系的实体,提升错误率,增加计算复杂度
交互缺失:忽略了两个任务之间的内在联系和依赖关系
1. pipline
1.1 NER
序列标注:SoftMax和CRF
每个token只能属于一个标签,不能解决重叠实体问题
采用token-level的多label分类,将Softmax替换为Sigmoid。这种方式会导致label之间的依赖关系缺失,可采用后处理规则进行约束
Neural Architectures for Nested NER through Linearization
采取CRF,但是设置多个标签层,然后讲所有标签层合并。增加lable数量,导致label不平衡问题
指针网络
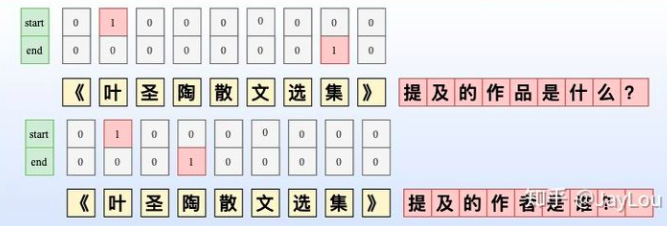
MRC-QA+单层指针网络(A Unified MRC Framework for Named Entity Recognition )
构建query问题指代所要抽取的实体类型,同时引入先验知识。
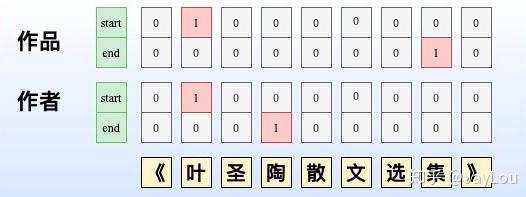
多层指针网络
构建多层指针网络,每层对应一个实体类型
注意:
- MRC-QA会引入query对实体类型编码,需要对原始文本重复编码以构造不同实体类型的query,将会大大增加计算量
- 多层指针网络(n个2元sigmoid分类),会导致样本tag空间稀疏,收敛较慢。
片段排列+分类(Span-Level Model for Relation Extraction)
针对Span排列的方式,显示所有可能的span排列,针对每个独立的span进行分类。由于选择的每个span都是独立的,所有该方式可以解决重叠实体问题。
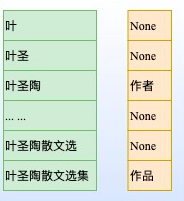
若文本过长,会产生大量的负样本,所以在实践中需要选择合理的span长度(窗口)。
Empirical Analysis of Unlabeled Entity Problem in Named Entity Recognition
利用负采样技巧,大大提升实体识别效果。
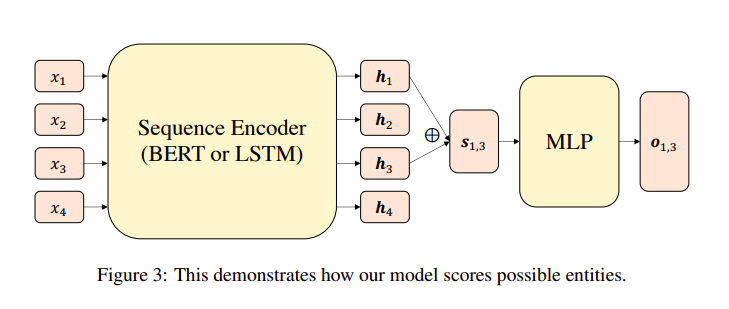
$$
s_{i, j}=h_i \oplus h_j \oplus (h_i-h_j)\oplus(h_i \odot h_j)
$$
MRC(A Unified MRC Framework for Named Entity Recognition)
实验证明,MRC效果的提升主要来自于基于自然语言的标签描述引入了更多的先验信息,对数据稀少的标签提升比较明显。
query问题设置标准比较模糊,不同的query构建方式导致不同的实验效果
针对一条样本,需要构造多个不同的query,重复编码,增加计算量
标签不平衡问题,真实场景下,大部分文本中只存在少量类别的实体,绝大部分query对对应了负样本。针对该,该团队提出了DSC loss,参考:Dice Loss for Data-imbalanced NLP Tasks
bi-affine(Named Entity Recognition as Dependency Parsing)
将实体识别任务转化为start和end索引问题,采用biaffine模型对句子中的tokens的start和end对进行评分。最终biaffine模型的输出为$l\times l\times c$ 的矩阵(l为句子长度,c为标签类别数)
$$
h_s(i) = FFNN_s(x_{s_i})
$$
$$
h_e(i) = FFNN_e(x_{e_i})
$$
$$
r_m(i)=h_s(i)^TU_mh_e(i)+W_m(h_s(i)\oplus h_e(i))+b_m
$$
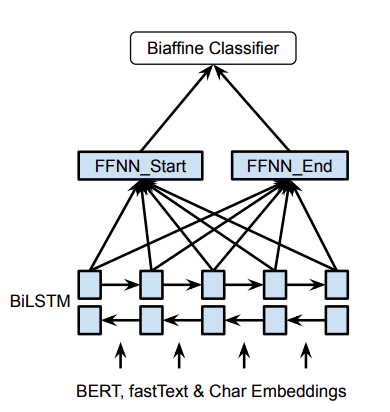
备注:
- 线性模型(linear): $Wx^T$
- 双线性模型(blinear): $xWy^T$
- 仿射模型(affine): $Wx^T+b$ 或者写作 $W[x:1]$
- 双仿射模型(bi-affine): $[x:1]W[y:1]$
1.2 关系分类
Matching the Blanks: Distributional Similarity for Relation Learning
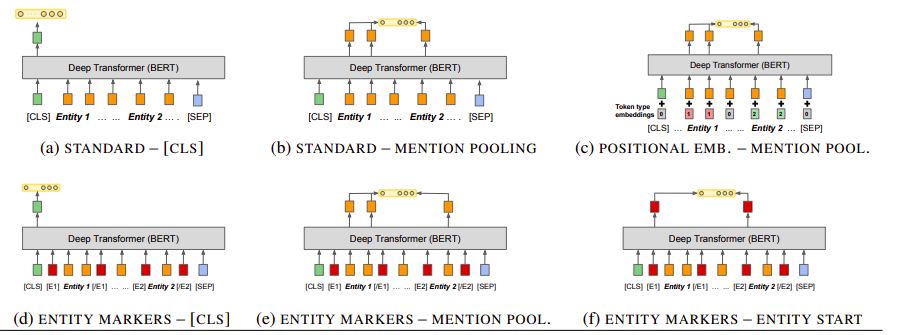
基于bert,采用6中不同结构来进行实体pair的pooling,然后讲pooling后的编码进行关系分类。实验显示(f)结果最好。
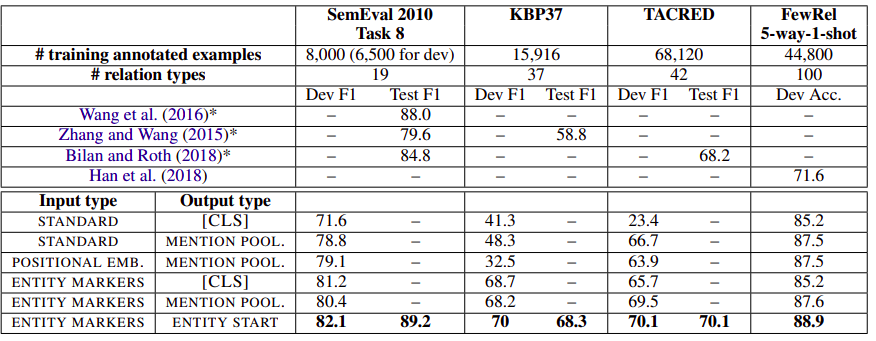
Extracting Multiple-Relations in One-Pass with Pre-Trained Transformers
Pipline方式下的关系分类,同一个句子通常会有多个不同的实体对关系,一般的做法是构造多个实体对,进行多次关系分类,本质是上一个muti pass问题,同一个句子会进行多次计算,增加计算时间。
本文将多次关系分类问题转化为one pass问题。一条样本输入模型,即可完成多个关系的分类。
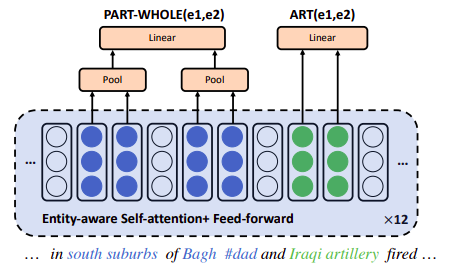
本文将还编码词和实体之间的相对距离计算Entity-Aware Self-Attention。$w_{d(i-j)}$ 代表实体$x_i$ 到token $x_j$的相对距离的embedding。
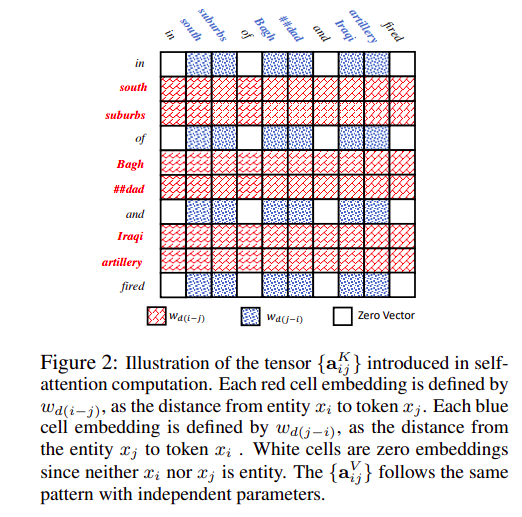
在标准self-attention的基础上增加了实体距离信息。
$$
Q_{south}=h_{south}W^Q
$$$$
K_{in}=h_{in}W^K+A^K_{south_in}
$$$$
V_{in}=h_{in}W^V+B^V_{south_in}
$$$$
Z_{south_in}=softmax(\frac{Q_{south}K_{in}}{\sqrt{d_{k}}})V_{in}
$$实体距离信息计算如下:
- if south is entity: $A^K_{south_in}=W^K_{d(index(south), index(in))}$
- if in is entity: $B^V_{south_in}=W^V_{d(index(south), index(in))}$
- else: $A^K_{south_in}=O$
Enriching Pre-trained Language Model with Entity Information for Relation Classification

Simultaneously Self-Attending to All Mentions for Full-Abstract Biological Relation Extraction
- 采用one-pass对所有实体进行关系分类,从所有实体mention中定位关系
- 文档级别关系抽取,引入NER辅助进行多任务学习
- 关系分类采用Bi-affine,而不是采用Softmax
使用Tansformer编码,对每个token通过两个独立的MLP进行三元组中的head和tail表征,最后使用Bi-affine计算每个三元组的得分。
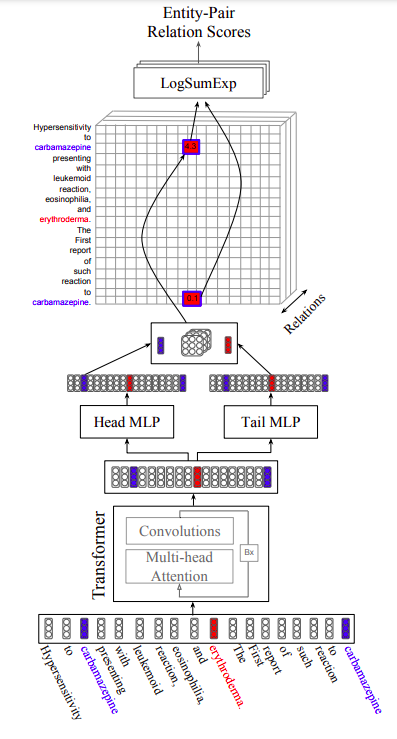
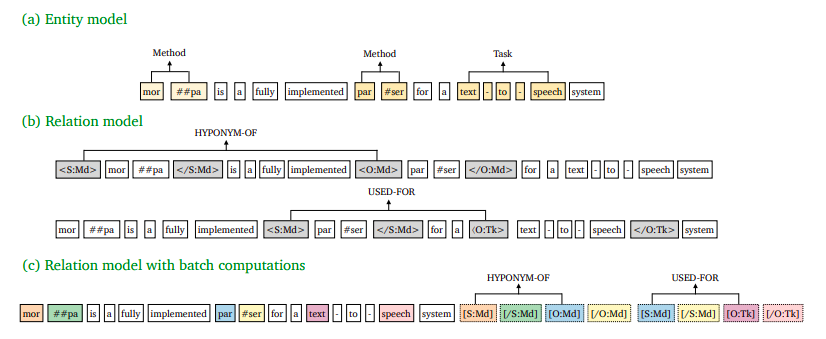
A Frustratingly Easy Approach for Joint Entity and Relation Extraction
实体模型采用Span-level NER的方式
关系模型:将实体边界和实体类型作为标记符加入到实体span前后
近似模型:将实体边界和标记符放到文本之后,与原文对应的实体共享位置向量。具体实现中,attention层,文本token只attend文本token,不去attend标记符token,而标记符token可以attend原文token。
跨句信息:通过窗口滑动的方式引入跨句信息,即文本输入的左右上下文中分别滑动$(W-n)/2$ 个词,n为文本长度,W为固定窗口大小。
attention mask实现:
1
2
3
4
5
6
7
8
9
10
11
12# Compute the attention mask matrix
attention_mask = []
for _, from_mask in enumerate(input_mask):
attention_mask_i = []
for to_mask in input_mask:
if to_mask <= 1:
attention_mask_i.append(to_mask)
elif from_mask == to_mask and from_mask > 0:
attention_mask_i.append(1)
else:
attention_mask_i.append(0)
attention_mask.append(attention_mask_i)1
input_mask = [1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0]
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0]
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0]
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0]
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1]
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1]
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1]
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1]
2. Joint Model
联合模型就是只有一个模型,将两个子任务统一建模。联合抽取可以进一步利用两个任务之间的潜在信息,缓解错误传播的缺点。
联合抽取的难点在于何如加强实体模型和关系模型之间的交互,比如实体模型和关系模型的输出之间存在一定的约束,在建模时考虑此种约束有利于联合模型的性能。
共享参数的联合模型
通过共享参数(共享输入特征或者内部隐藏状态)实现联合,这种方式对子模型没有限制,但是由于使用独立的解码算法,导致实体模型和关系模型之间的交互不强
联合解码的联合模型
2.1 共享参数的联合抽取方法
基于参数共享的联合抽取方法的解码主要包括:序列标注CRF/Softmax、指针网络、分类Softmax、seq2seq等。最终的loss为实体loss和关系loss相加。
多头选择+sigmoid: Joint entity recognition and relation extraction as a multi-head selection problem
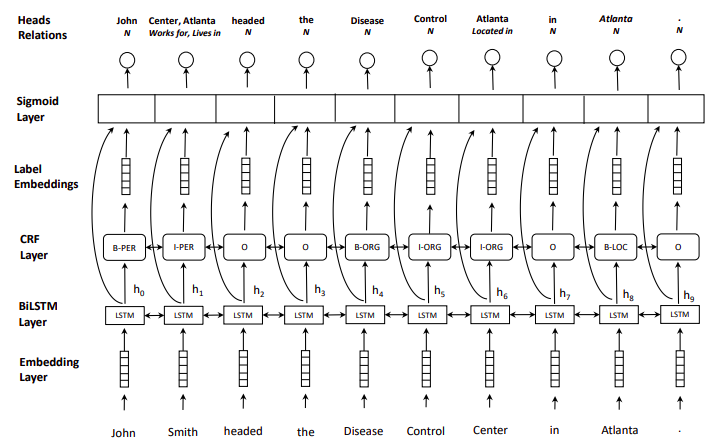
先抽取实体,再利用实体边界信息进行关系抽取
实体抽取:BIO标注,CRF解码
关系抽取:sigmoid多头选择。对于含有n的token的句子,最终构成的关系矩阵为$n\times r \times n $ ,其中r为关系数。
引入实体识别后的entity label embedding(BIO)进行关系抽取,训练是使用gold label,预测时使用predict label。
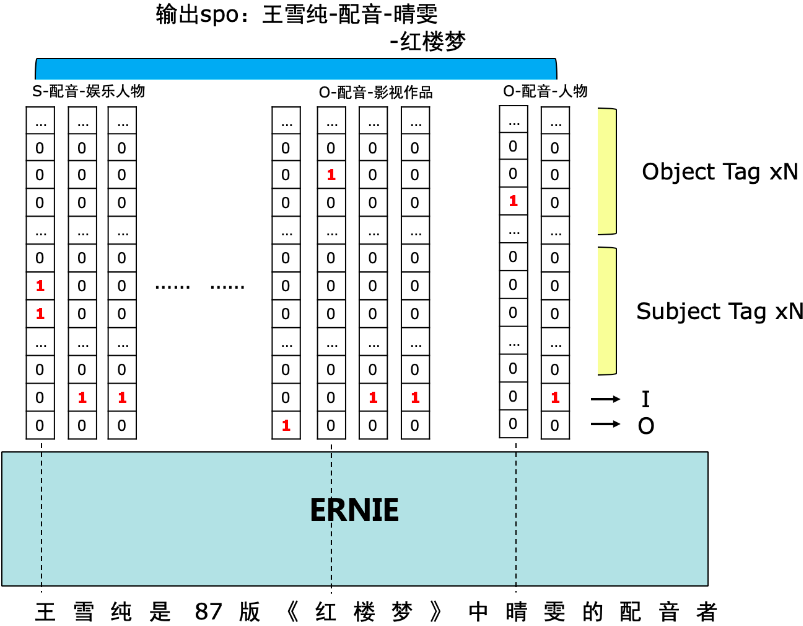
SPO+指针网络: Joint Extraction of Entities and Relations Based on a Novel Decomposition Strategy
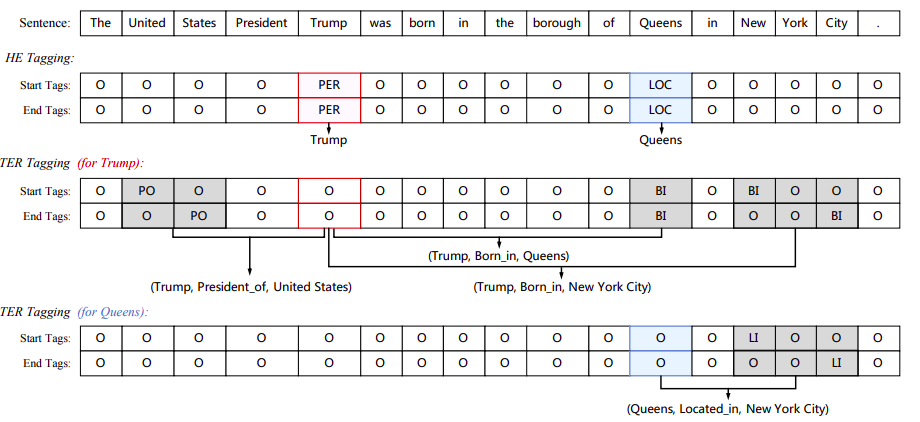
spo问题,先抽S,再抽PO
在训练时,subject的选取是随机的,并没有将所有的subject统一进行po抽取,所以需要增大epochs训练,保证训练充分。ps:可以遍历的方式训练所有的subject(大约能提高1个百分点)
LIC2020冠军方案
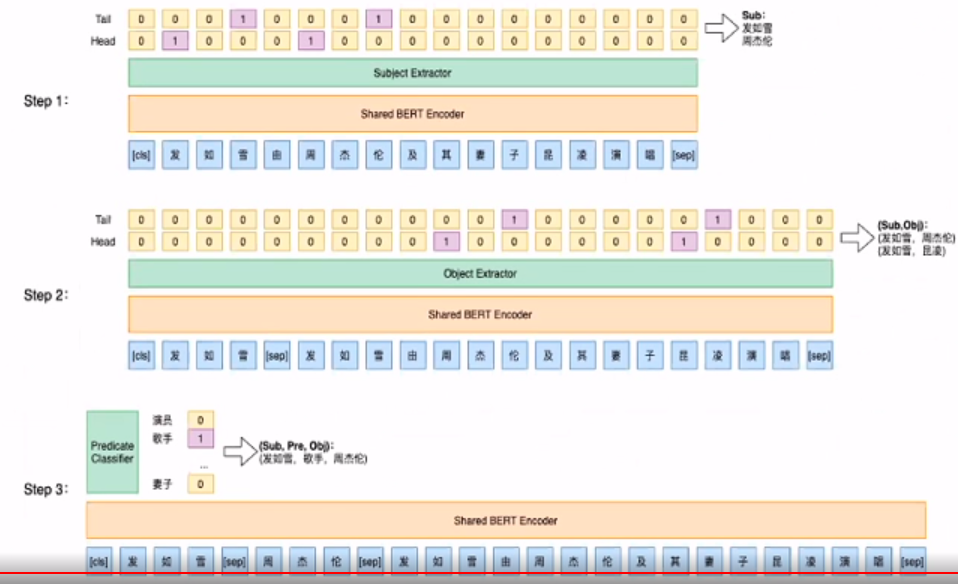
- spo抽取,先抽s,再抽o,最后抽取p
- 随机的把subject加到句子的开头,用sep分割组成新的输入,预测o。预测p同理
2.2 基于联合解码的联合抽取方法
基于共享参数的联合抽取方法中,并没有显示的刻画两个任务之间的交互。同时,训练和预测仍然存在gap。
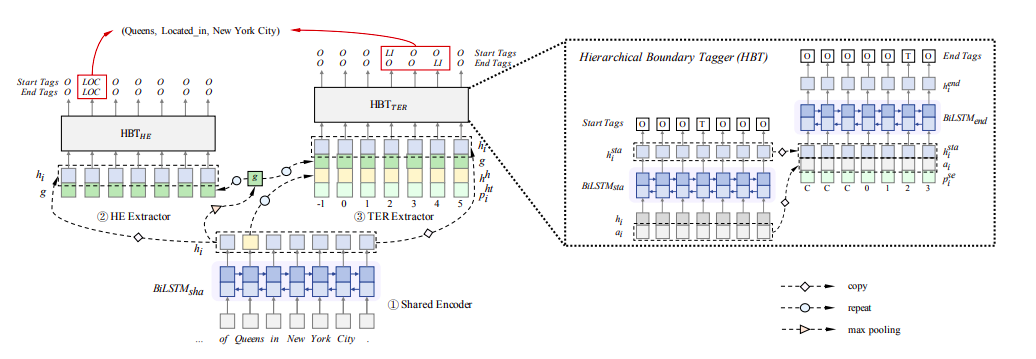
Joint Extraction of Entities and Overlapping Relations Using Position-Attentive Sequence Labeling
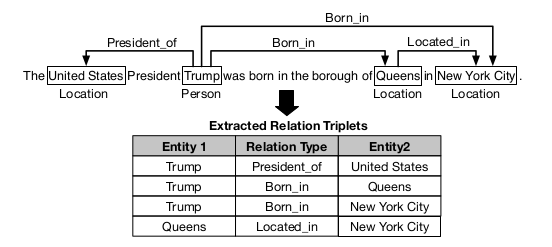
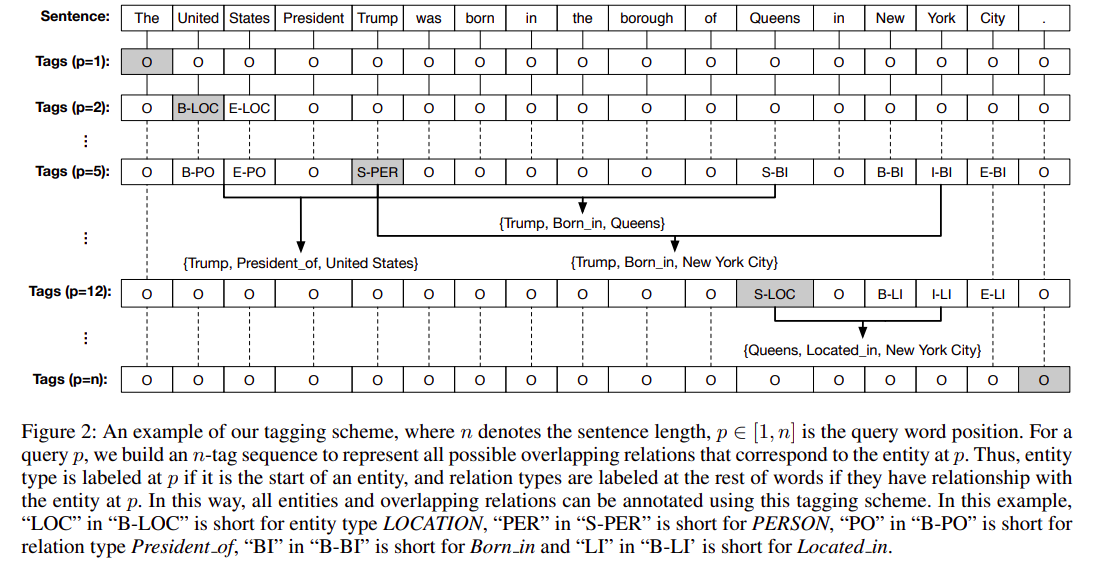
标记过程如下:
对于含有n个token的句子,为每个token创建一个长度为n的序列并标记,所以总共会标注n个长度为n的序列。根据不同的查询位置p(目标单词所在句子中的位置)对n个不同的标记序列进行标记
- 若查询位置p在实体的开始处,则在p处标记实体的类型
- 若p处的实体为subject,则在与p处实体有关系的其他实体(object)用关系类型标记
- 若p处的实体为object,则其余位置标记为“O”
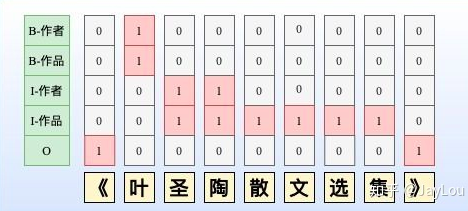
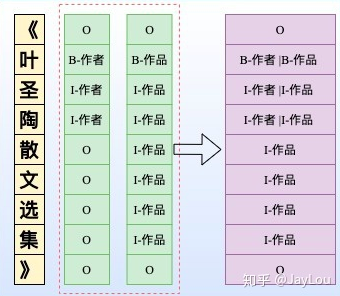
Joint extraction of entities and relations based on a novel tagging scheme
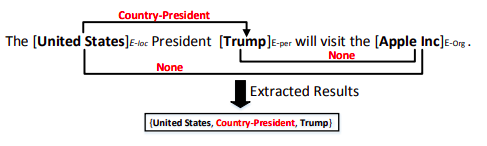
该方案是LIC2020和LIC2021关系抽取的baseline方案,统一了实体和关系的SPO标注框架
- token level的多标签分类,单个token对应多个不同的label
- 假定存在R个关系,则label一共有(2*R+2)个。
- 该框架不发解决实体重叠的关系抽取
TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking
TPLinker整体标注框架是基于token pair进行的,本质上是一个span矩阵(类似于多头标注、bi-affine)。
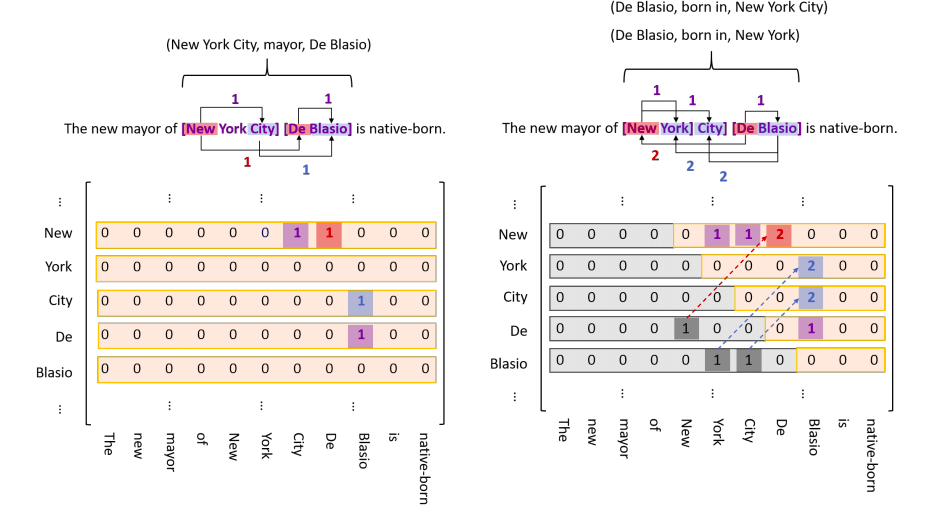
TPLinker通过链接三种类型的span矩阵来实现编码(关系类别总数为R)
- 紫色标注:EH to ET,表示实体的首位关系,表示为一个$N \times N$ 的矩阵,如两个实体:New York City:M(New, City) =1; De Blasio:M(De, Blasio) =1
- 红色标注:SH to OH,表示subject和object的头token的关系,表示为R个$N \times N$的矩阵。如三元组(New York City, mayor,De Blasio):M(New, De)=1
- 蓝色标注:ST to OT,表示subject和object的尾部token间的关系,表示为R个$N \times N$矩阵;如三元组(New York City, mayor,De Blasio):M(City, Blasio)=1
最终,会得到2*R+1个矩阵。为防止稀疏计算,下三角不参与计算,如果关系存在与下三角,则将其转置为上三角,并将标记1替换为2.
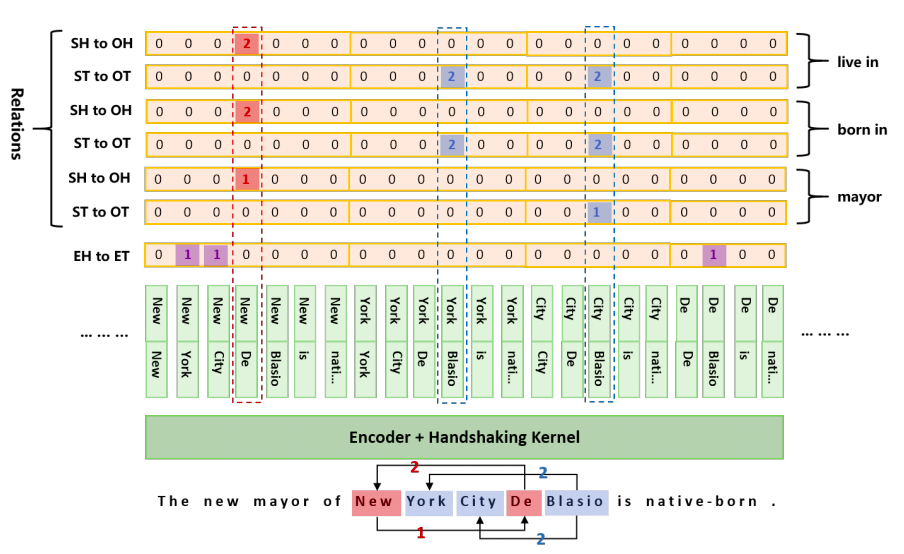
通过解码结构可以看到,每个token pair对应了2*R+1个label。对于N个token的序列,最终会展开为一个$N \times (N+1)/2$ 的 序列,也就是将token pair的每个token编码拼接在一起。ps:一般来说,显卡都是支持不了一次性预测$N \times (N+1)/2$的序列,源码中设置了参数p(0-1),表示为单轮预测序列长度为:$N \times p$
解码过程为:
- 解码EH-to-ET可以得到句子中所有的实体,用实体头token idx作为key,实体作为value,存入字典D中;
- 对每种关系r,解码ST-to-OT得到token对存入集合E中,解码SH-to-OH得到token对并在D中关联其token idx的实体value;
- 对上一步中得到的SH-to-OH token对的所有实体value对,在集合E中依次查询是否其尾token对在E中,进而可以得到三元组信息。
结合上图的具体case,我们具体描述一下解码过程:
解码EH-to-ET中得到3个实体:{New York,New York City,De Blasio}; 字典D为:
{New:(New York,New York City),De:(De Blasio)}以关系“mayor”为例,
- 解码ST-to-OT得到集合E:{(City,Blasio)}; 解码SH-to-OH得到{(New,De)},其在字典D中可关联的subject实体集合为: {New York,New York City};object集合{De Blasio};
- 遍历上述subject集合和object集合,并在集合E中查询尾token,发现只有一个实体三元组{New York City,mayor,De Blasio}
以关系“born in”为例,
- 解码ST-to-OT得到集合E:{(Blasio,York),(Blasio,City)};解码SH-to-OH得到{(De,New)},其在字典D中可关联的subject实体集合为{De Blasio};object集合为{New York,New York City};
- 遍历上述subject集合和object集合,并在集合E中查询尾token,可得到2个实体三元组:{De Blasio,born in,New York}和{De Blasio,born in,New York City}
由于关系live in与born in一样,所以我们最终可得到5个三元组:
(New York City, mayor, De Blasio), (De Blasio, born in, New York), (De Blasio, born in, New York City), (De Blasio, live in, New York), (De Blasio, live in, New York City)